
2023 summary
My graphics programming focus this year was mostly on SDF evaluation and splat rendering but I did have some fun side projects!
January
At the start of the year I was working on the sdf-editor and not a ton of context was saved because I didn't have this website and I wanted the results to be a surprise. This was a huge mistake, I need to get better at showing progress externally.


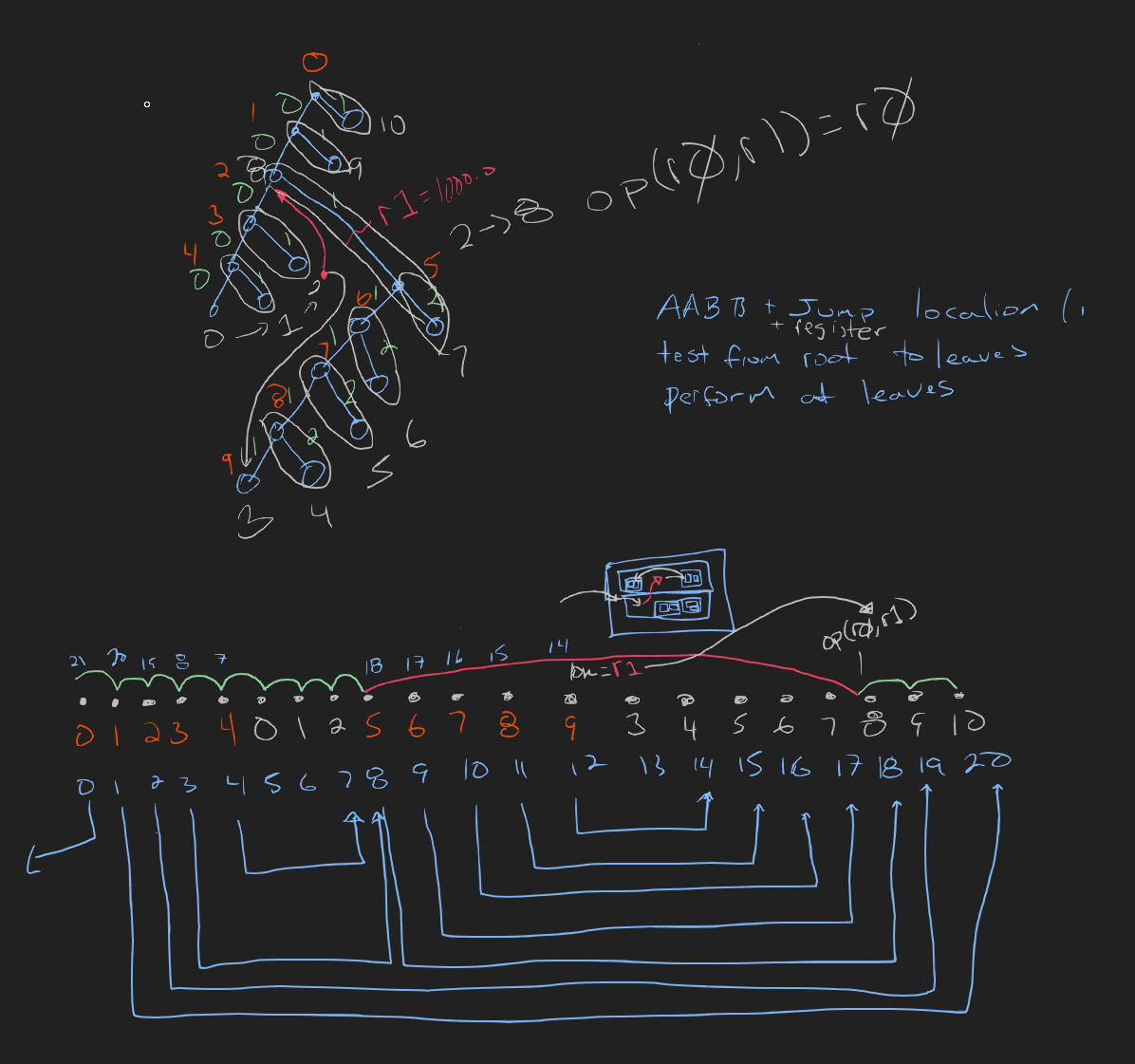
more register based musings
Suffered from a simple change (adding a couple properties) that ballooned into larger refactor. The problem was that there is no easy way to find all of the places a property needs to be referenced or copied. This refactor moved me towards using non-optional switch() statements that force every enum to be present. This adds more code, but atleast adding a propery that needs to be plumbed through the system will cause compile time errors instead of having to find all of the issues at runtime.
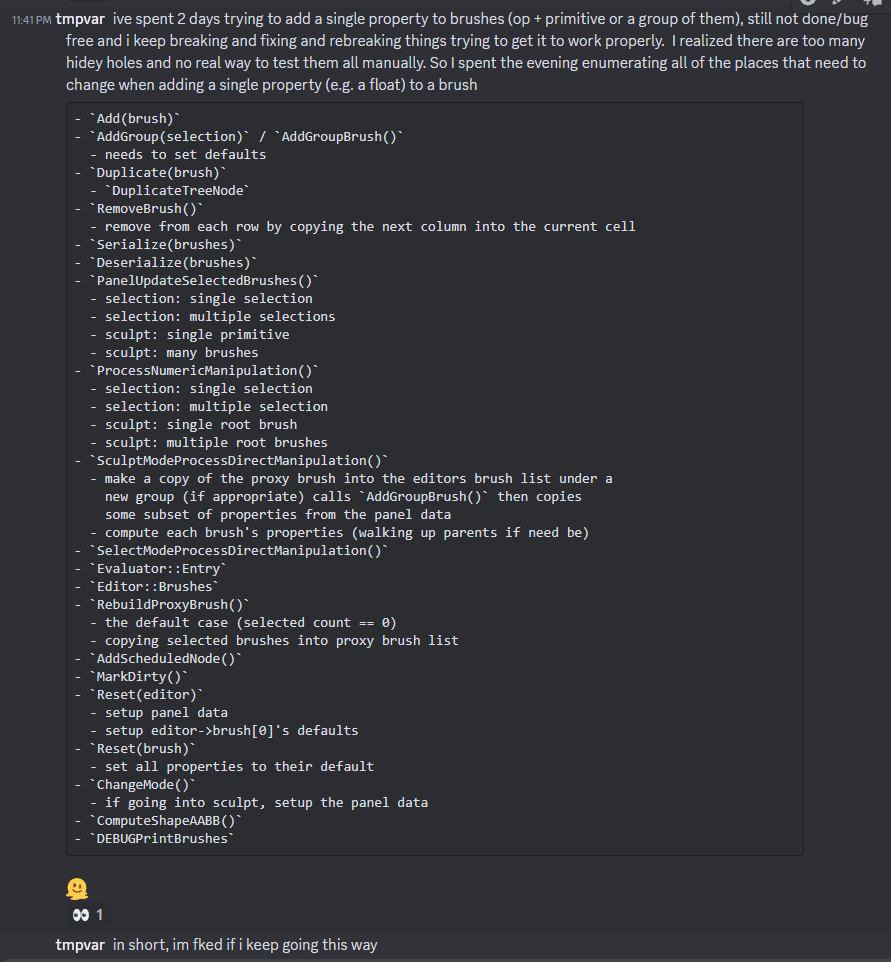
the issue and the resulting madness
Februrary
I needed a distration and happened to watch a Pezza's work video Writing a Physics Engine from scratch - collision detection optimization where they show a very large number of particles interacting. I got nerd sniped!
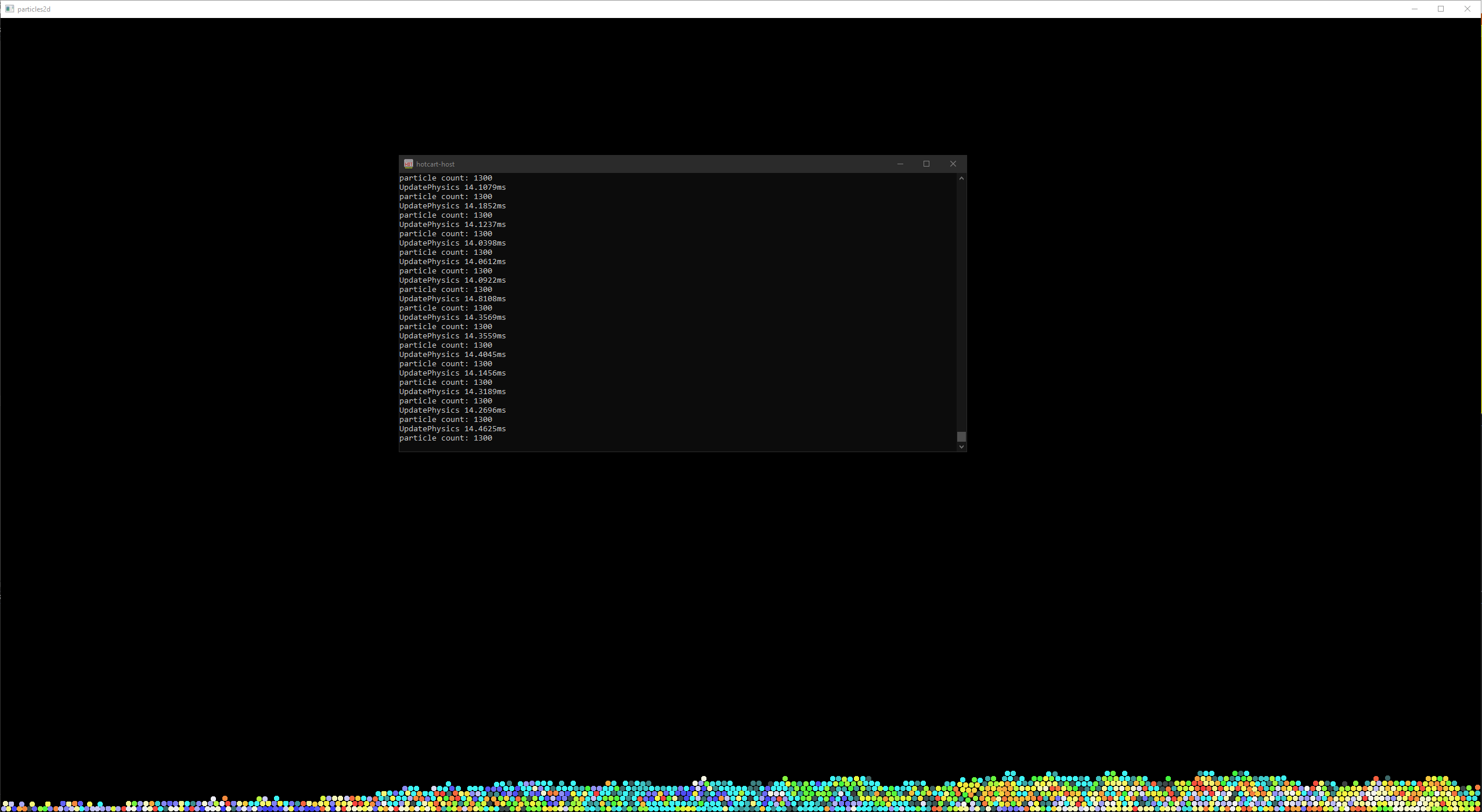
~14ms for 1300 particles, ew!
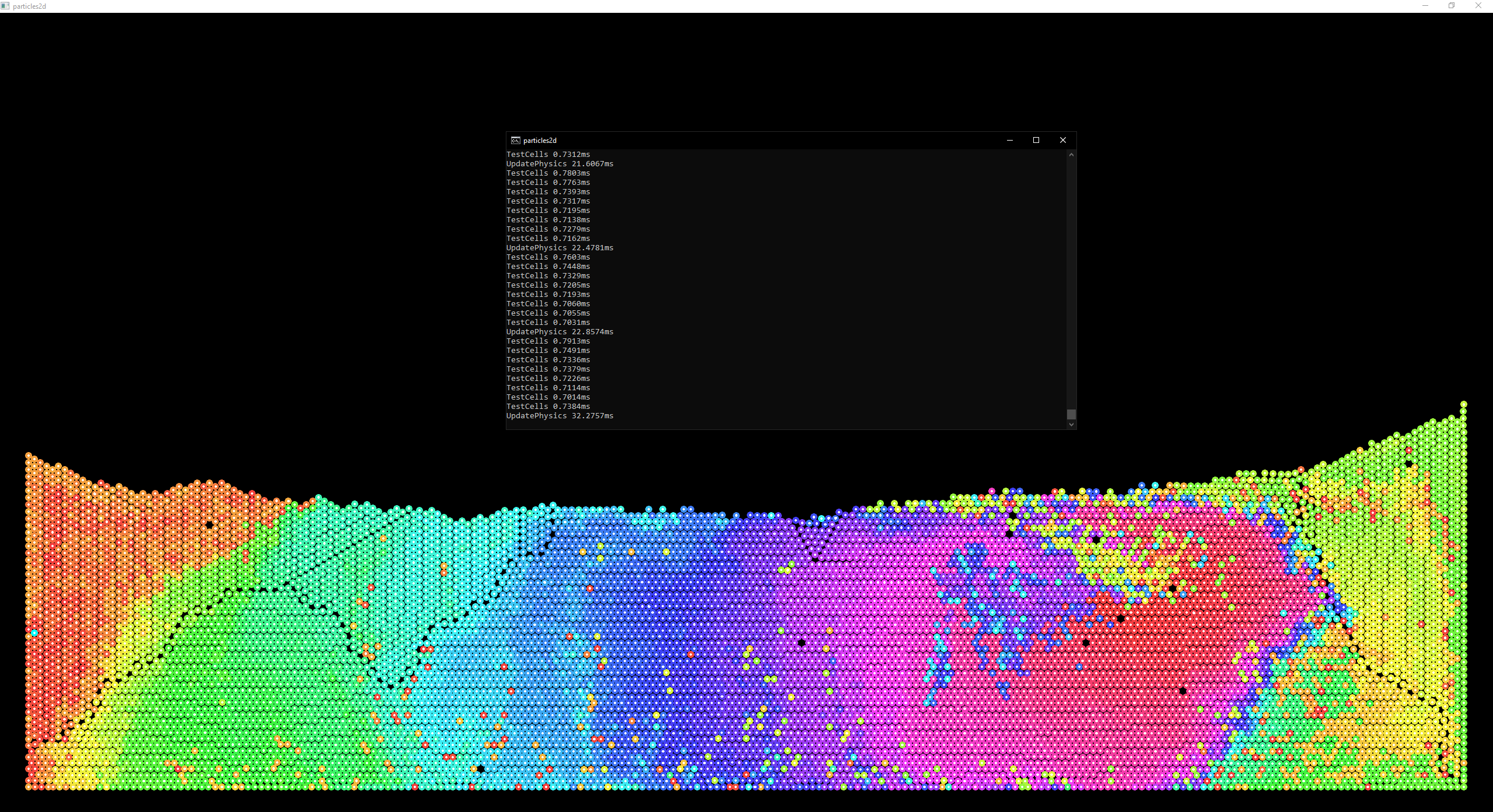
~20ms for 10,000 particles by reducing the grid size
~10ms for 40,000 particles by building the grid once per frame and using AVX2
on a single thread
And then it was back to the sdf-editor, which I was working on in parallel with the particle sim.
March
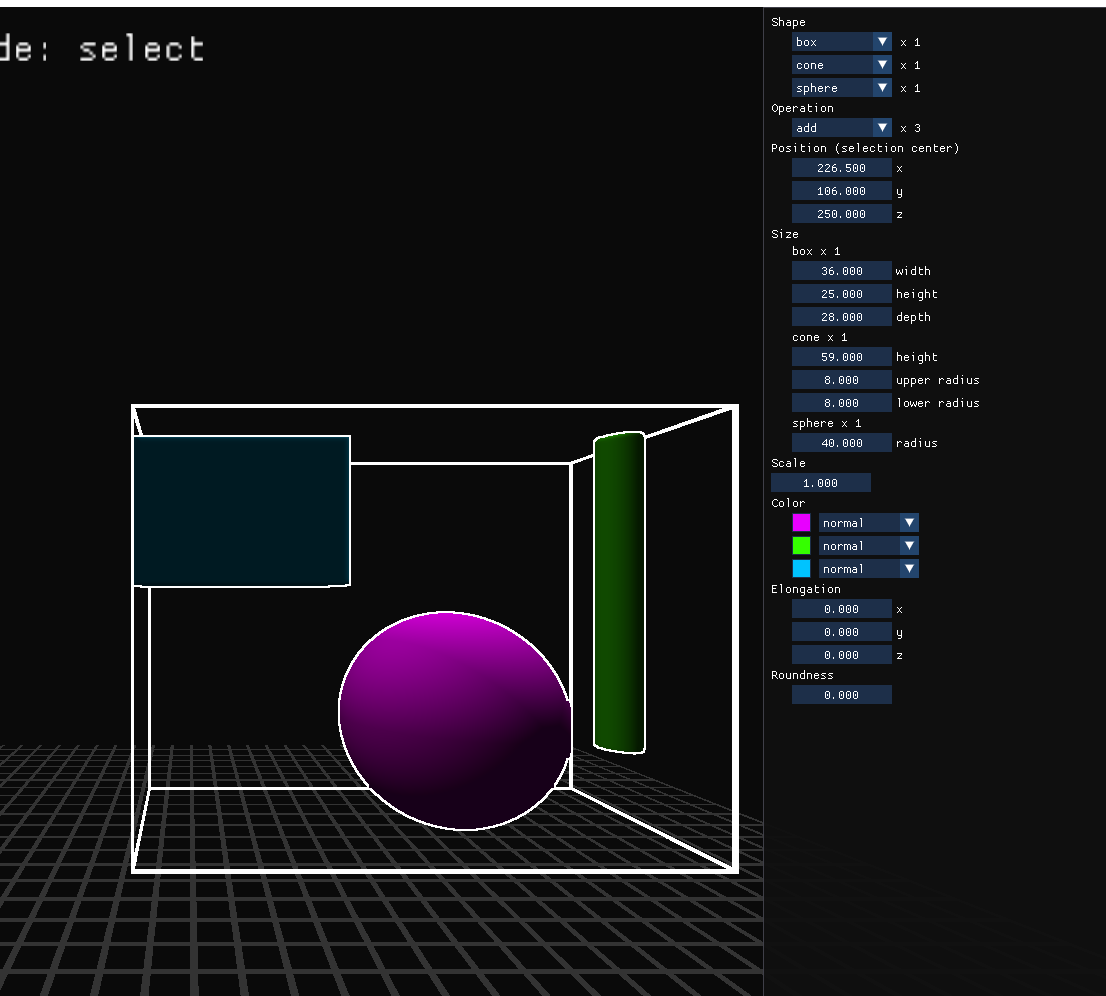
making the panel handle multi-select
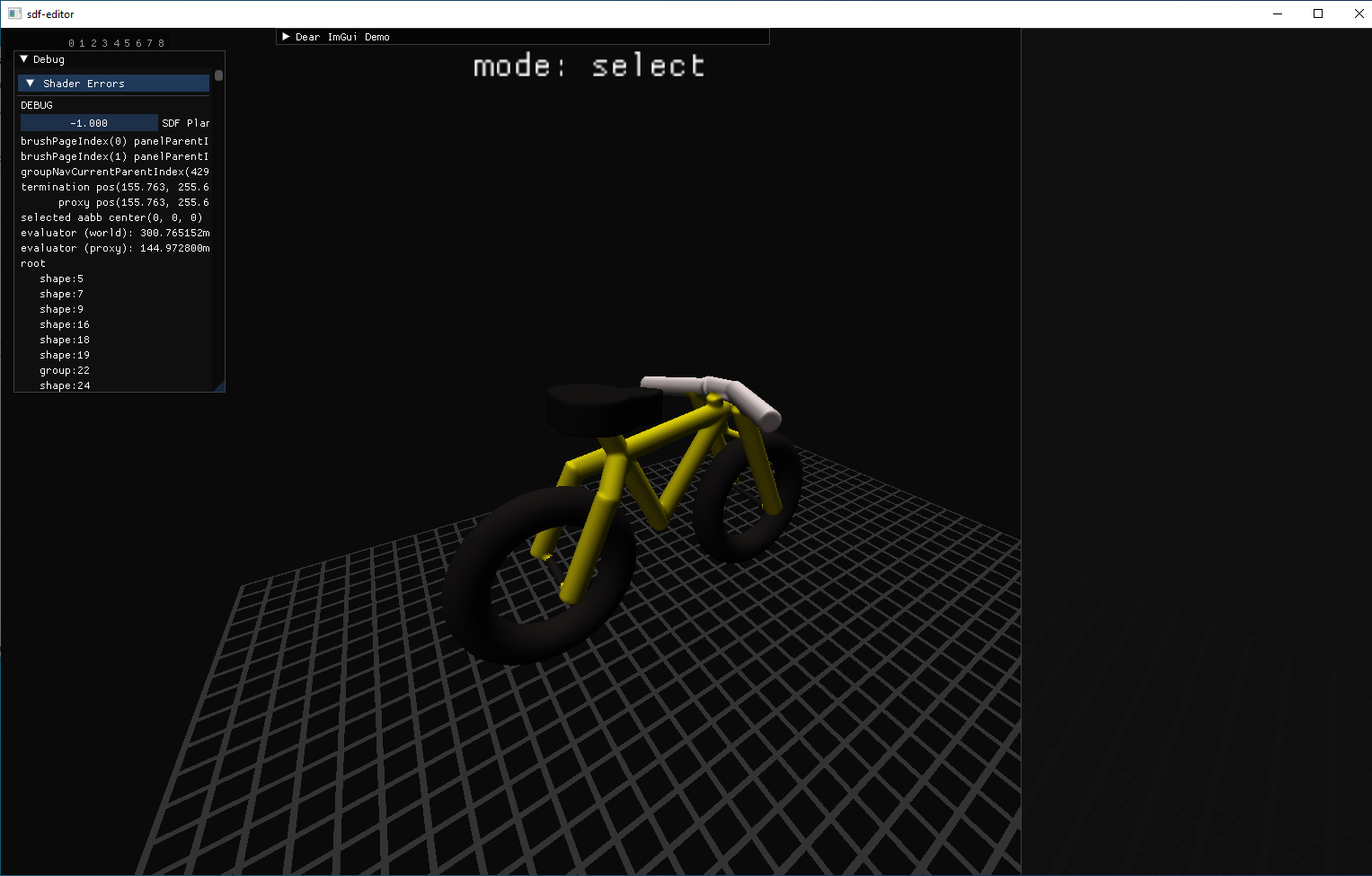
pre-alpha user testing
takeaway: this thing is pretty hard to use
Some things were wearing on me with the sdf editor
- Objects were limited to the size of the voxel box they were contained in. I believe this was 5123
- In my user testing people found it hard to manipulate objects
- After ~200 objects everything became laggy
- The elephant in the room: composite brushes made it much more complex to optimize the evaluator, re-enforcing the 200 object limit.
- Controls / Panel were somewhere inbetween direct manipulation and precise control like you'd see in CAD, but it did neither very well. I think there is room in an editor to do both, but I missed the mark on this one.
So, I scrapped the whole thing and started designing a new system that wouldn't be forced to live inside of a voxel grid. My first thought was of panic because living on a grid is comfy. You don't have to worry about isosurface extraction and all of the degeneracies (e.g., topological issues, manifold issues) or the optimization of connecting graphs together to save on vertex bandwidth.
So after taking another glance at the current state of the art which seemed like Digital Surface Regularization With Guarantees, I noticed that in their paper they have missing triangles!
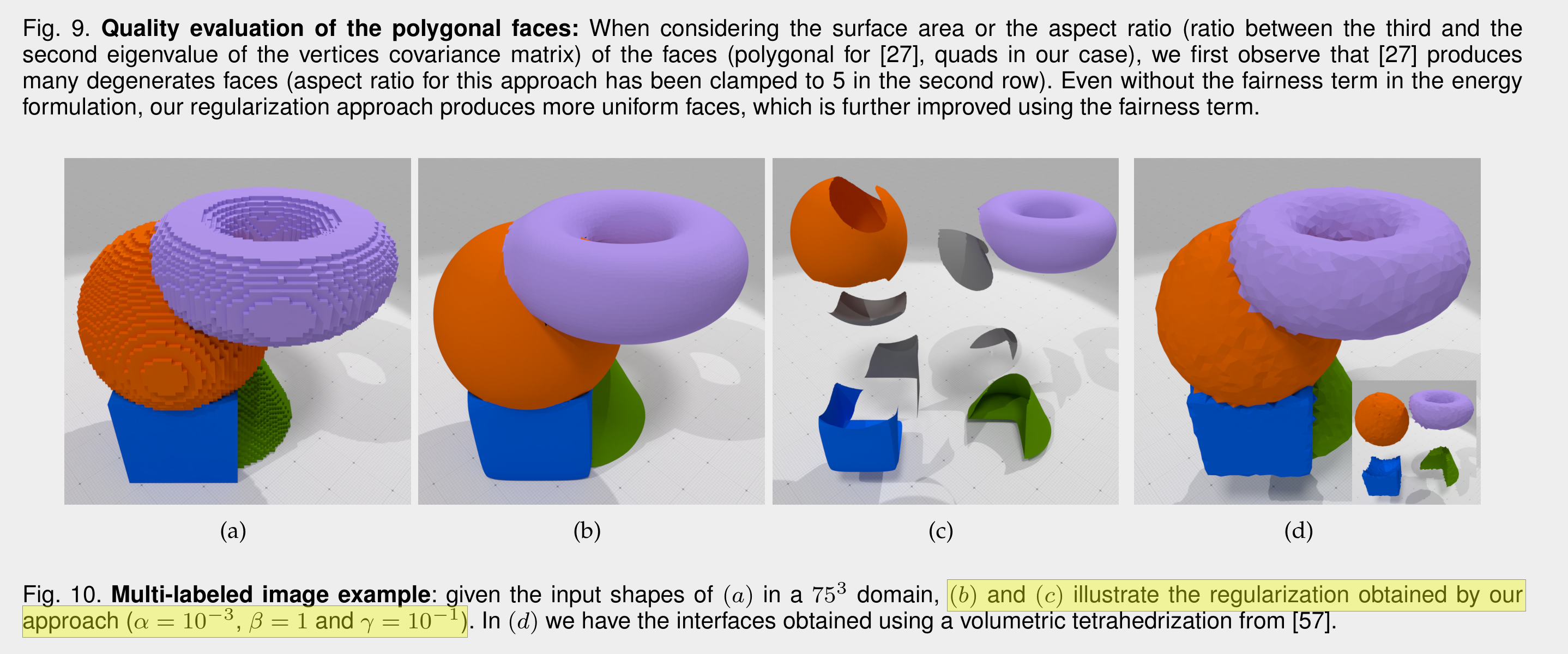
Anyway, I watched Alex Evan's Learning From Failure talk again and though I'd give max-norm a try. One thing that I thought would be a showstopper is if I couldn't figure out how evaluate objects that had been rotated under the max-norm distance metric.
According to Simon Brown the distance metric for a rotated object is the same as finding the largest aligned cube within a unit rotated cube (see: the Max norm ellipsoid shadertoy).
So I gave that a shot and came up with these two things:
-
TODO: I made these before this website was launched, so it would be beneficial to port them over

A plane of rotated boxes
Euclidean single thread 1223ms boxes(561) steps(14794498) leaves(4056562)

A plane of rotated boxes
MaxNorm single thread 1037ms boxes(561) steps(14090824) leaves(3812840)

scene(plane of boxes and spheres)
Euclidean/Scalar single thread 186ms primitives(561) steps(22517064) leaves(6307840)
Euclidean/IntervalArithmetic single thread 386ms primitives(561) steps(20804936) leaves(5726208)
MaxNorm single thread 291ms boxes(561) steps(20804936) leaves(5726208)
scene(plane of rotated boxes)
Euclidean/Scalar single thread 211ms primitives(561) steps(14793252) leaves(4055356)
Euclidean/IntervalArithmetic single thread 1053ms primitives(561) steps(19905185) leaves(5364673)
MaxNorm single thread 167ms boxes(561) steps(14089012) leaves(3811412)
April
After a brief stint writing a gpu evaluator, I turned my focus back to CPU evaluation because it is more general purpose. It is easier to run headless and on older machines. At this point the major downside of the evaluator is that it still operated over a fixed sized grid, building an octree. However, the multithreaded octree building approach that I was considering for the GPU scared me into avoiding it on the CPU.

64k random boxes
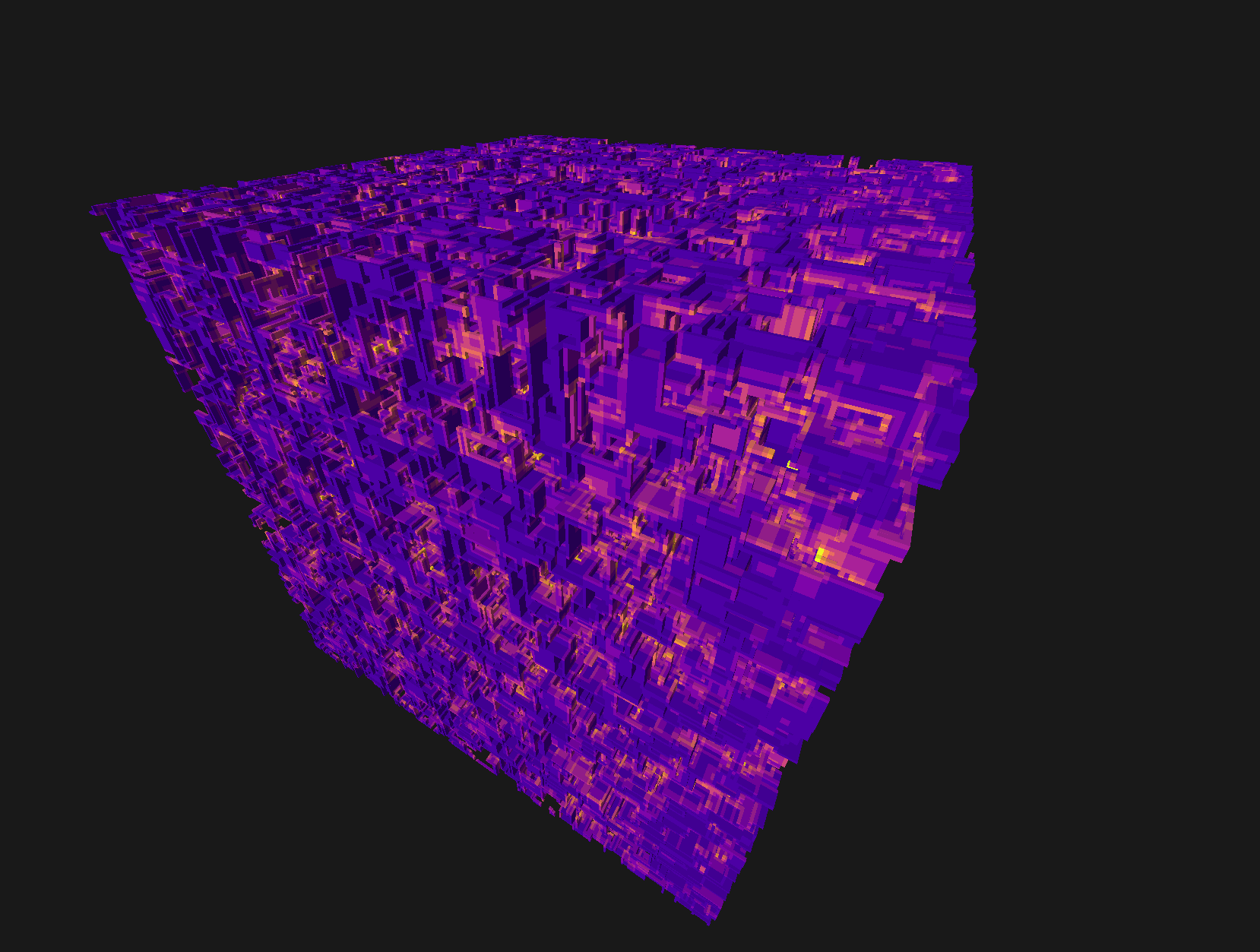
64k random boxes - heatmap for primitive overlaps (1..8)
I came up with the notion of having each thread running over an implicit grid, filtering primitives based on the grid cell and if there were overlaps then the thread subdivides the cell recursively to find the leaves. On the cpu this makes a ton of sense because we have large caches and stacks are basically free. By limiting the size of the chunks we also limit the depth of the traversal which makes tuning this with a single knob possible.
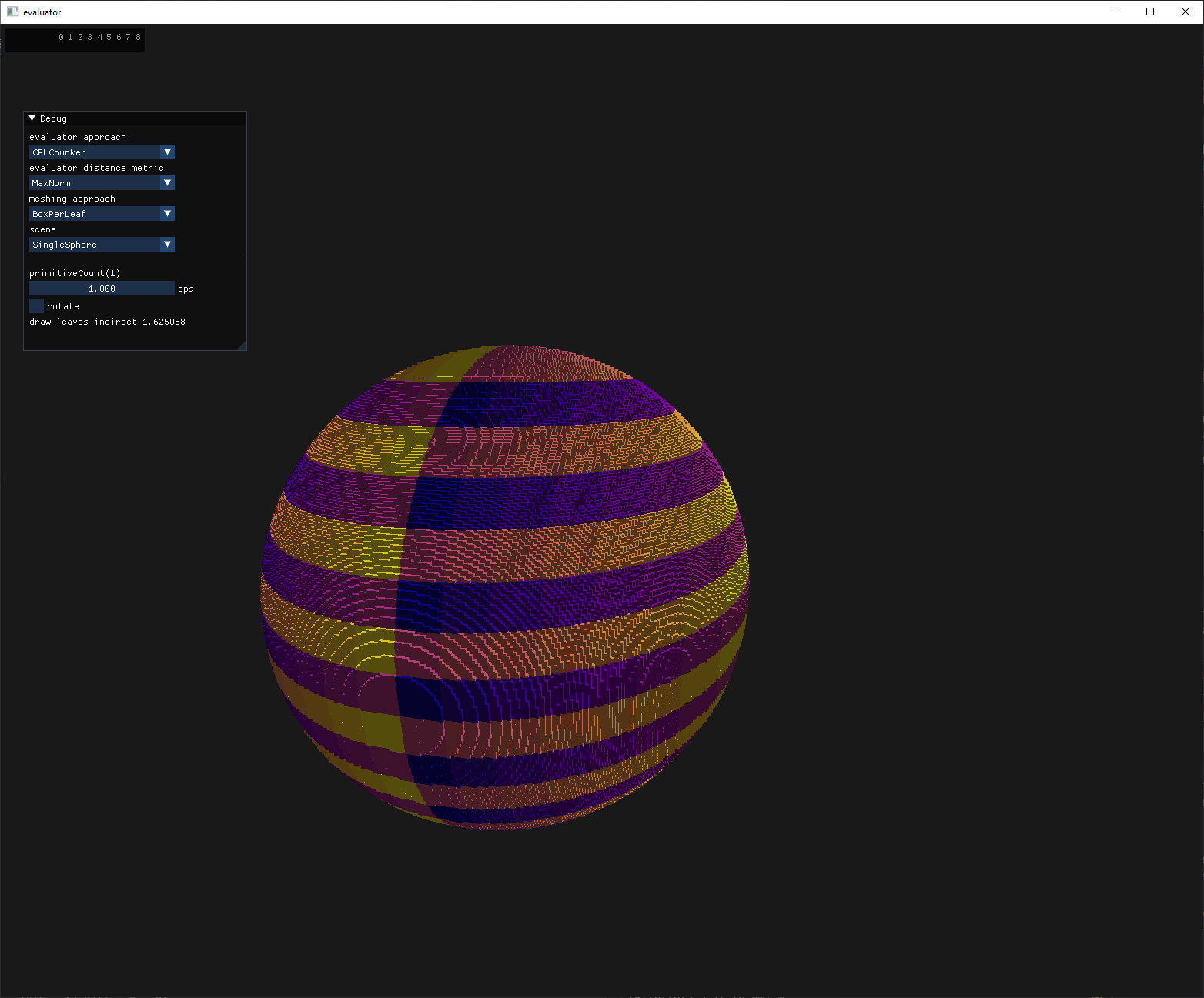
The ChunkerTM

identifying the chunks associated with regions of the sphere
box of rotated boxes

finally I've broken free of world size limits
At this point things were working pretty well, but my meshing strategy was a mess. Each chunk was being meshed, and since we don't know whats going on in the neighborhood (without dependency tracking or some other complexity) the mesher would mesh the inside and the outside of the isosurface. This effectively means that we're paying double the cost for meshing and double the cost for rendering.
To improve on this I thought back to one of many invaluable tips that Sebastian Aaltonen mentioned on twitter about generating cube vertices in a vertex shader. By implementing this I was able to reduce the meshing time by ~80% (354ms -> 81ms) and the rendering time by ~60% (40ms -> 16ms) for 15 million leaves!

May
// tweak the svo sampler to pull out some of the lattice
static f32
ChunkSVOSample(const ChunkSVO *svo, i32 x, i32 y, i32 z) {
if (x < 0 || y < 0 || z < 0 || x >= 64 || y >= 64 || z >= 64) {
return 1.0f;
} else {
return 0.0f;
}
}
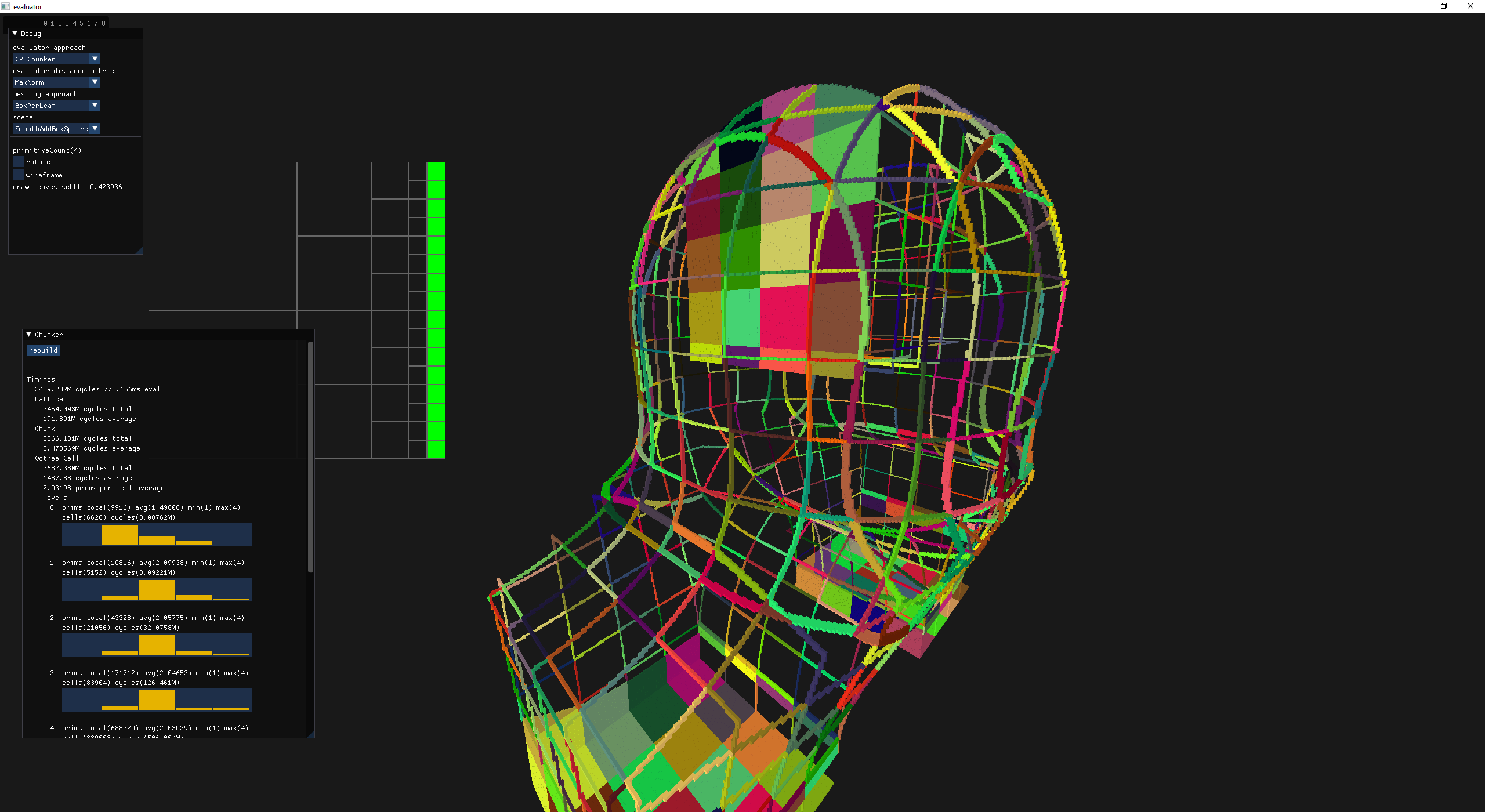
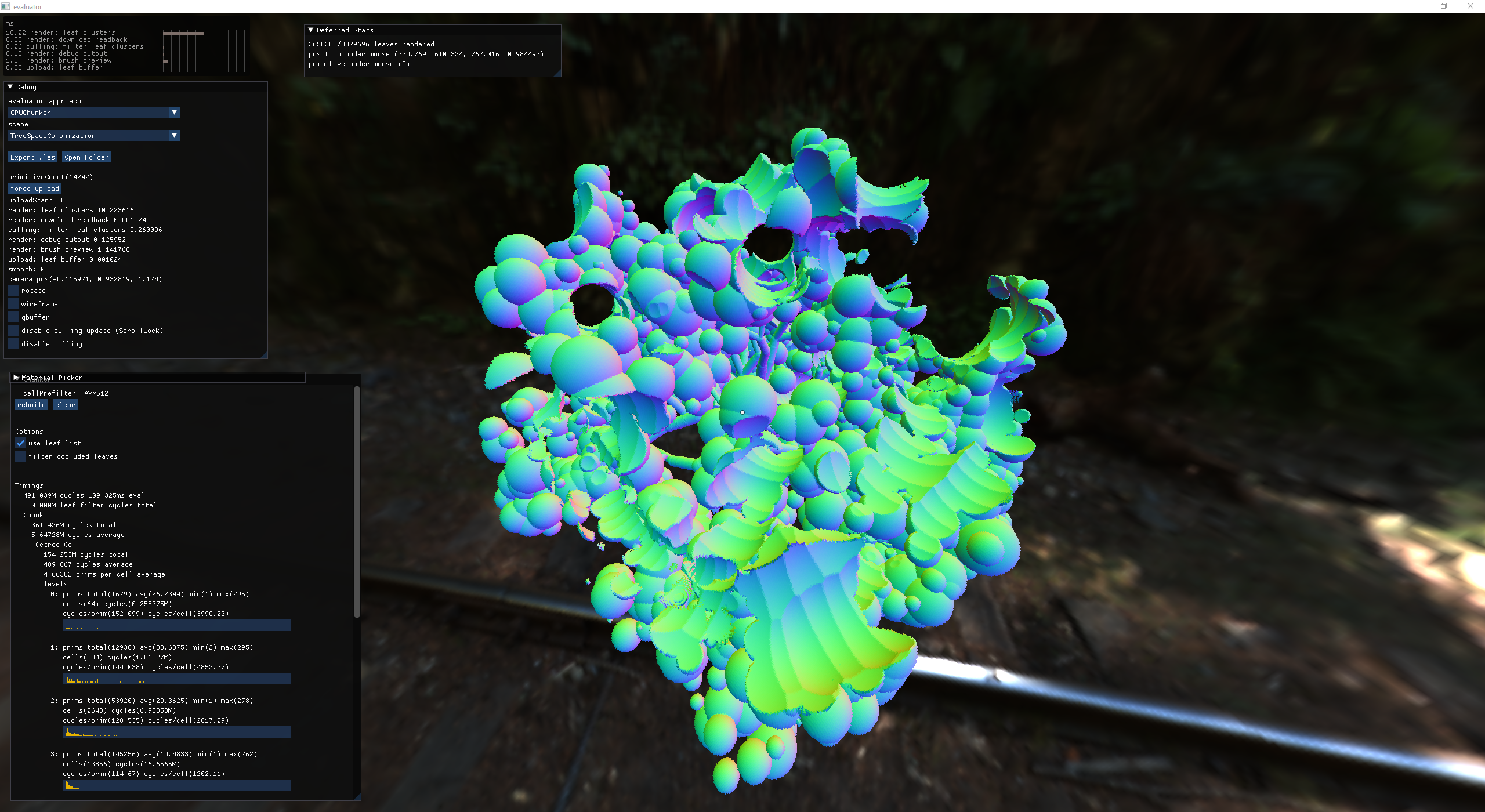
Now, the next thing bugging me was my lack of understand of how the evaluator was working in the octree. It still wasn't super fast, but I didn't have any data to inform how to optimize. So I decided to shine some light on what the evaluator was doing at each level of the octree by aggregating the data into a histogram.
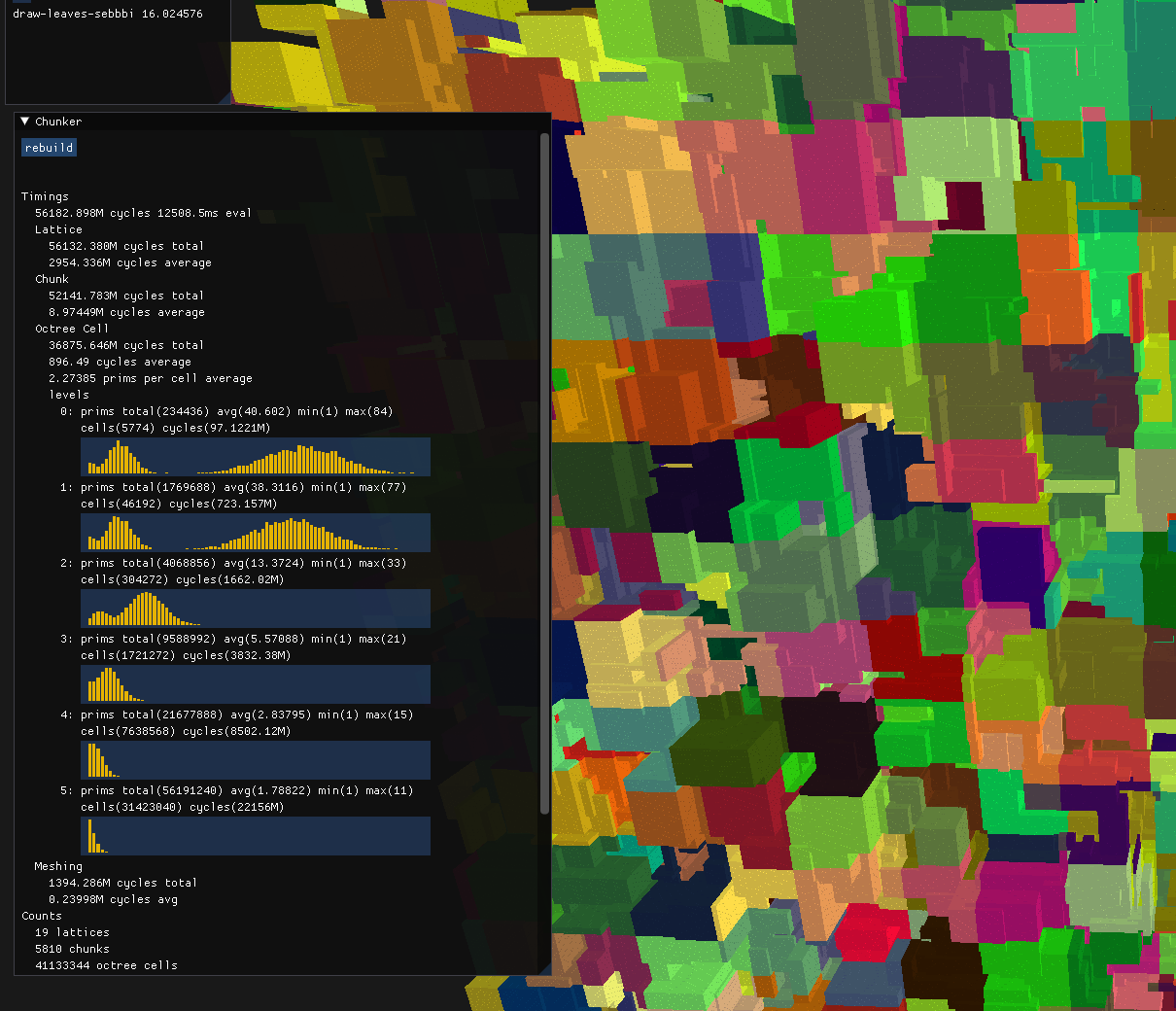
Chunker histogram
At level 0, the prims per cell is the highest, but this ratio quickly drops down and we end up swapping from performing many primitive evaluations per cell to many cell evaluations against very few primitives.
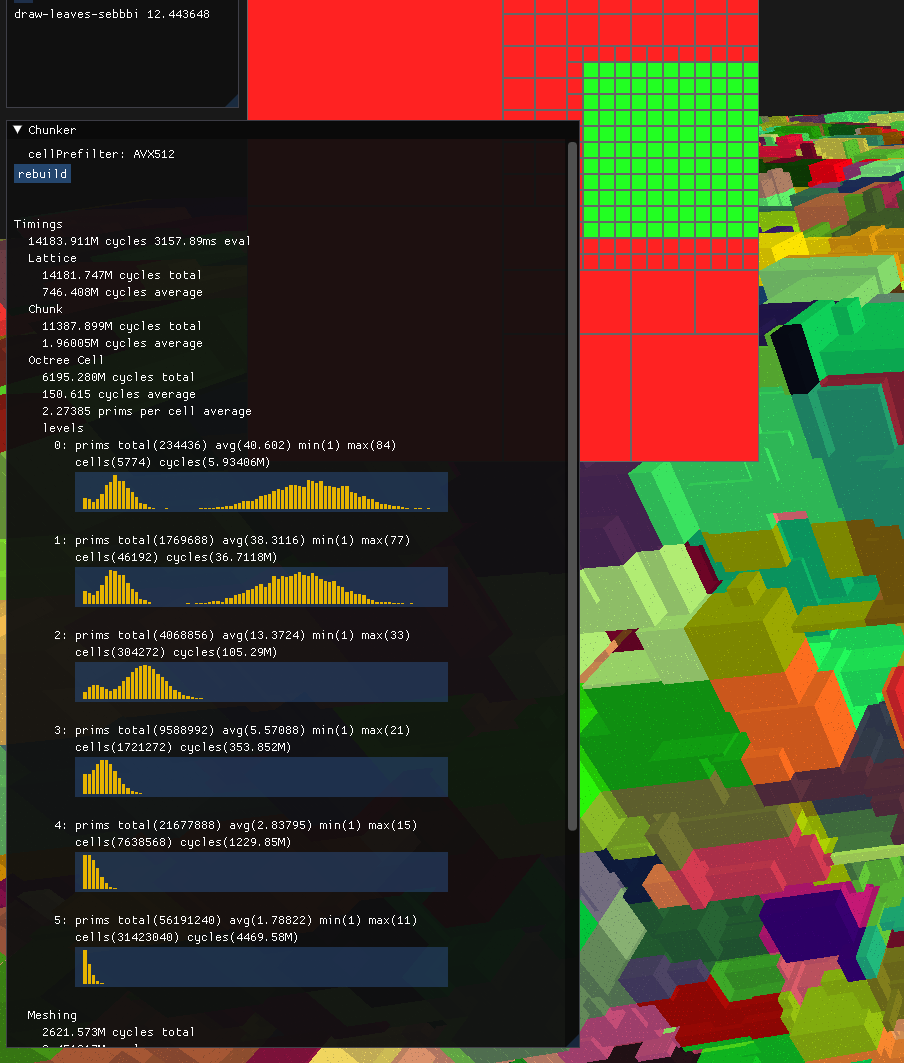
4x faster with very basic avx512 usage
Prefiltering primitive bounding boxes against the chunks
Initially I wrote the visualization side of the evaluator as just a way to debug what it was doing. As things progressed and I added more and more functionality to it, I realized that this thing was actually fast enough to use interactively.

added g-buffer support
added leaf id to the g-buffer

deferred image based lighting

deferred image based lighting

bug with normals for added primitives

fixed bug with normals for added primitives
Now that I had a g-buffer, we turn once again to Sebbbi's twitter, this time for Hi-Z Culling. The basic idea is that you use the previous frame's depth buffer to cull objects in the current frame that would be behind last frame's objects.

hi-z culling from GPU-Driven Rendering Pipelines
Results:
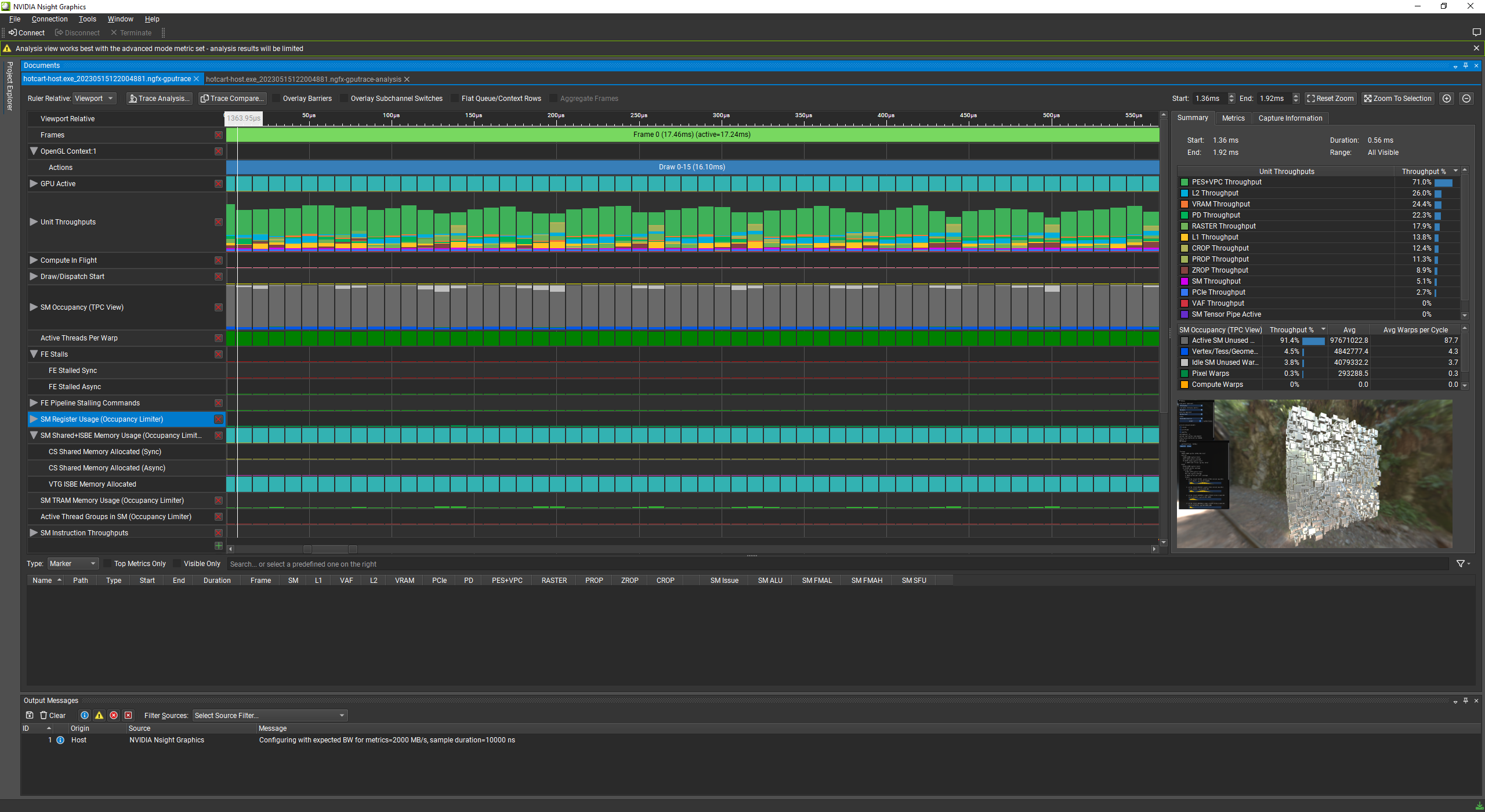
before hi-z culling: 16ms per frame
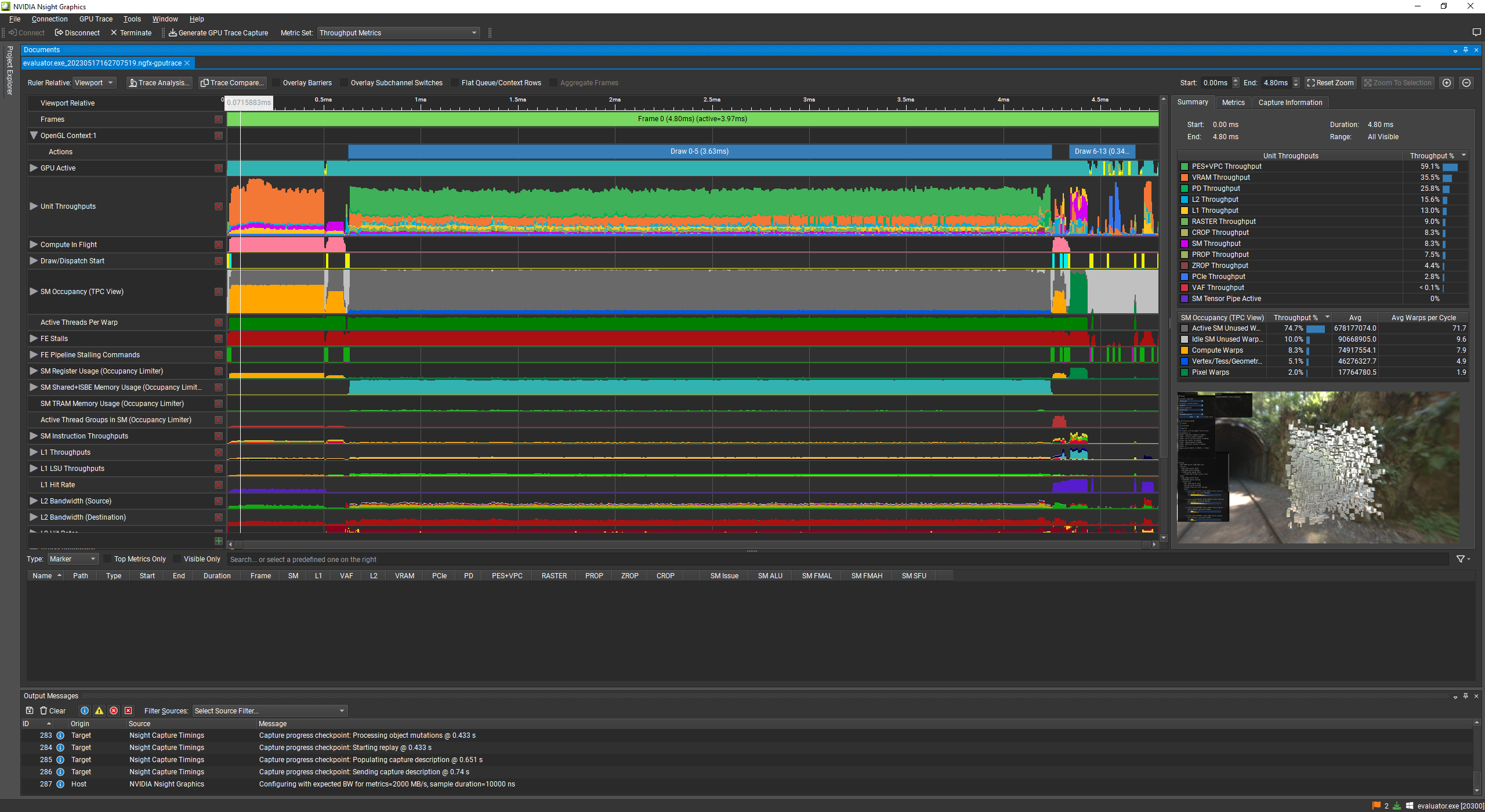
after hi-z culling: 3.6ms per frame
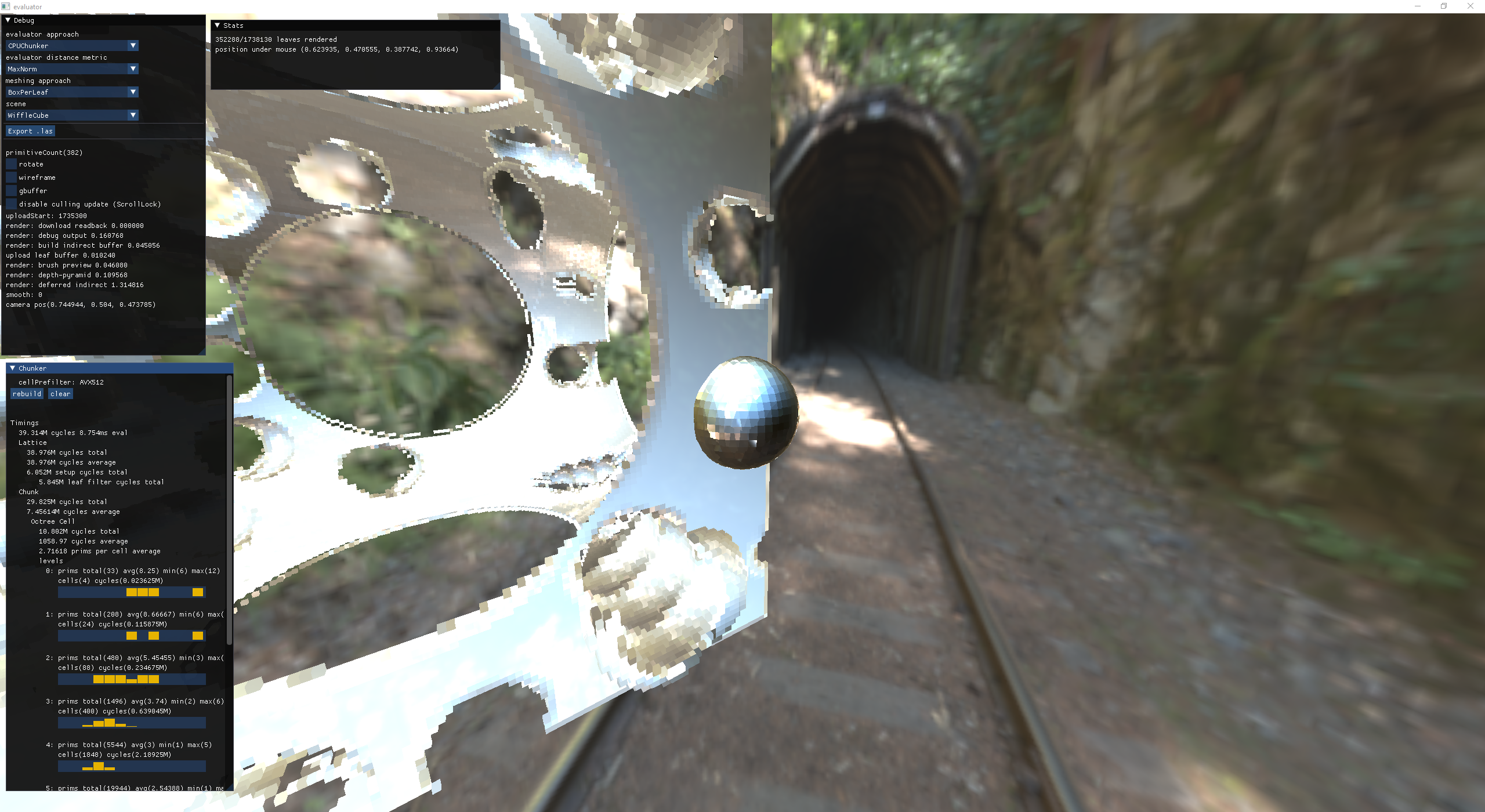
brush preview: additive sphere
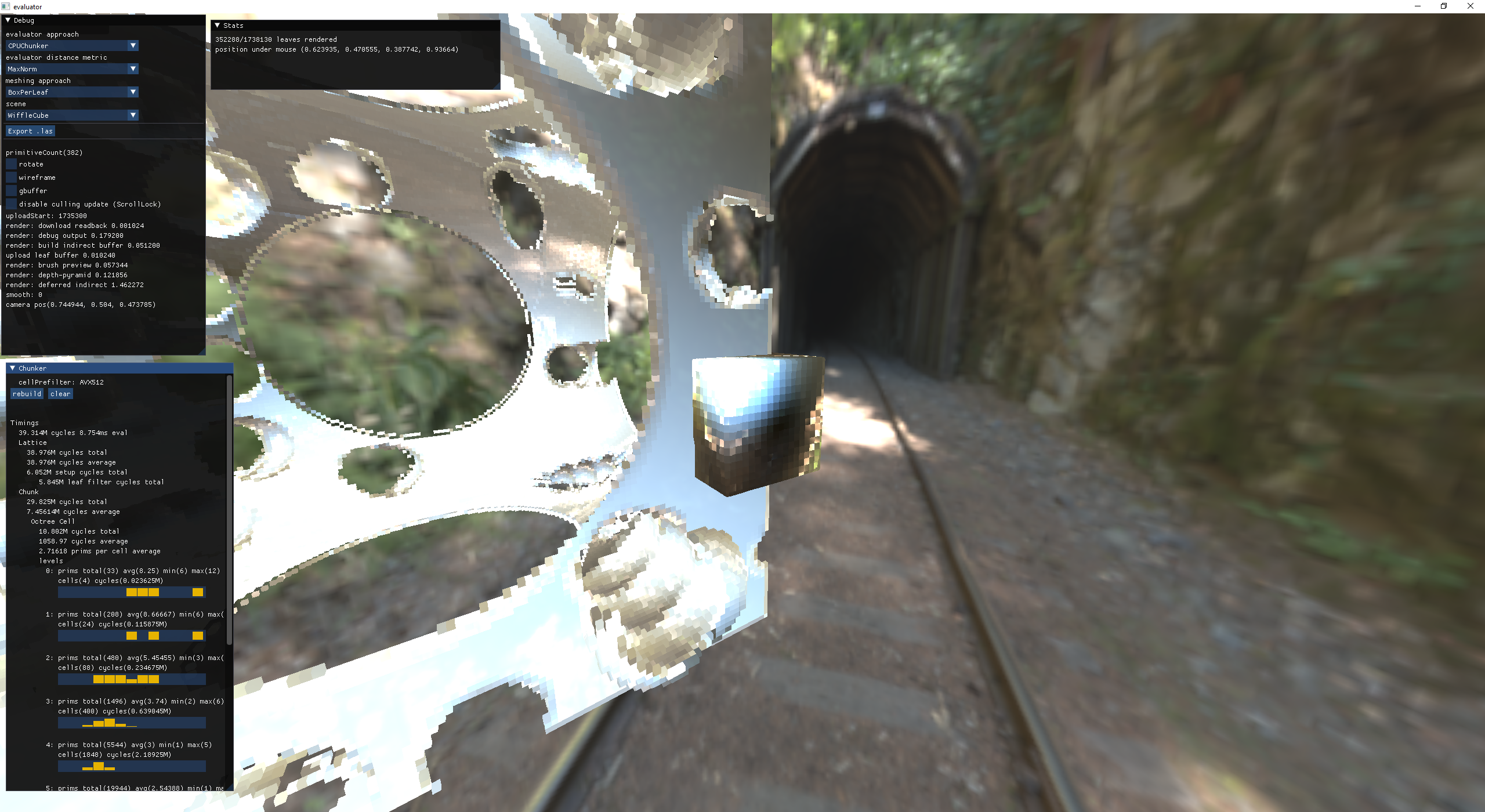
brush preview: additive cube
So at this point, the brush preview was functional and the brush itself was locked to the surface under the mouse. So it was time to try and actually use the thing to make something other than squiggles.

my first sculpt with this system
The main issue with the system at this point is finding the surface under the mouse. I was doing a readback from the GPU which was causing a noticable lag. So I spent some time trying to optimize that readback, but was unable to get it to feel right. I'll probably have to revisit this at some point.
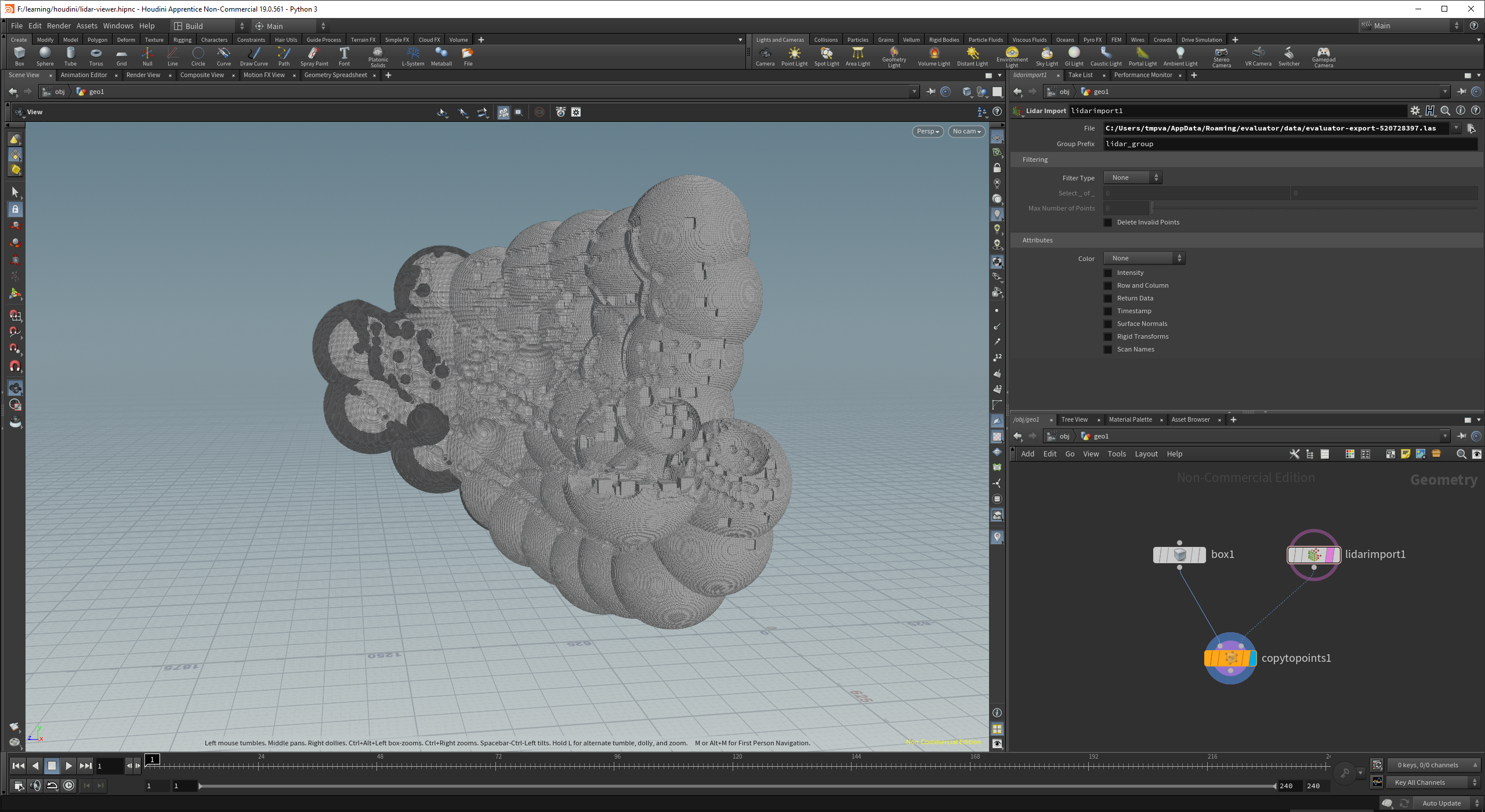
.las file (LIDAR) exporter and houdini import
video by @rh2 - drawn in my puny sdf editor, simulated in houdini, and rendered in blender
check out their awesome SBSAR (substance designer) materials on swizzle.fun
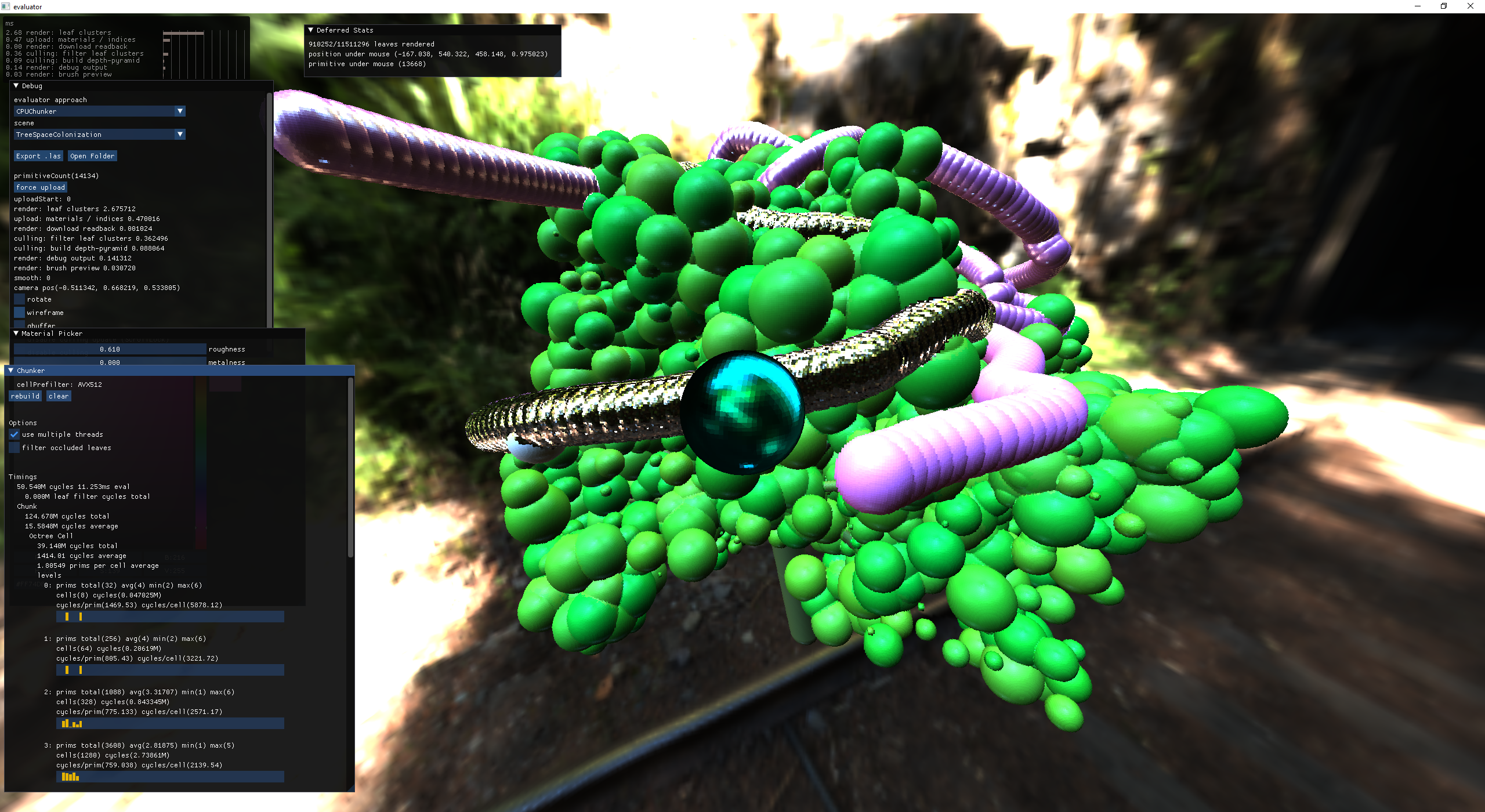
At this point I'm really happy with the performance and how fast it is to spam new primitives. The chunker made evaluating dirty/new regions super convenient. So I started adding support for materials, starting with global materials just to prove that I had the pipeline setup and things looked reasonably close to what I'd expect. My assumption is that this is a rough pass that I'll have to keep iterating on.

gold-like material

plastic-like material
With the global materials working, it's time to attach a material to every leaf based on the associated primitive!

graph coloring of primitive id for material color

editable materials
And because we now have user selectable color, the .las exported gets support.
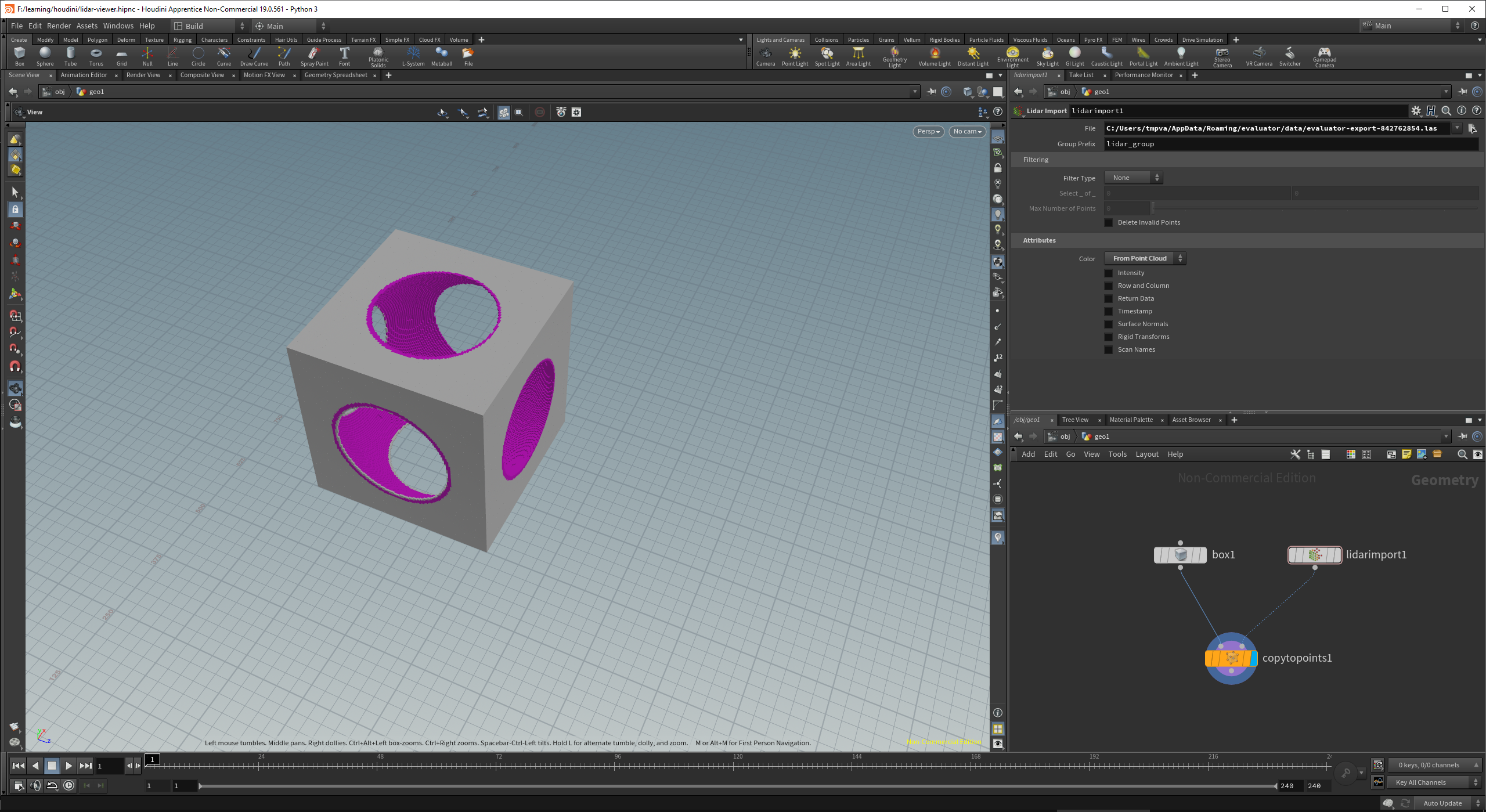

cuts take the cutter material
Learning from the earlier user testing of the earlier sdf editor, I opted to start working on a menu that can house all of the actions you can take. Hotkeys can be added later. The idea was a multi-level radial menu, in the pixel art aesthetic.

radial menu
Well that worked really well, how about tackling the brush manipulation problem?

global vs local transform icons
June

janky max-norm lines based on Segment - distance L-inf

toadstool life (aka I added cones!)
I was having some trouble making things that looked really good by hand, and I knew that I wanted some trees so I decide to look into how to procgen some trees.


a generated tree

a generated tree with leaves (spheres) @ 30k total sdf primitives

leaf filter + better colors

inside looking out
And of course we can't leave the .las exporter out. The above tree exports to ~6M points @ 170MB (download the 16MB zip here). This really makes houdini struggle, maybe they should invest in some Hi-Z Culling haha.
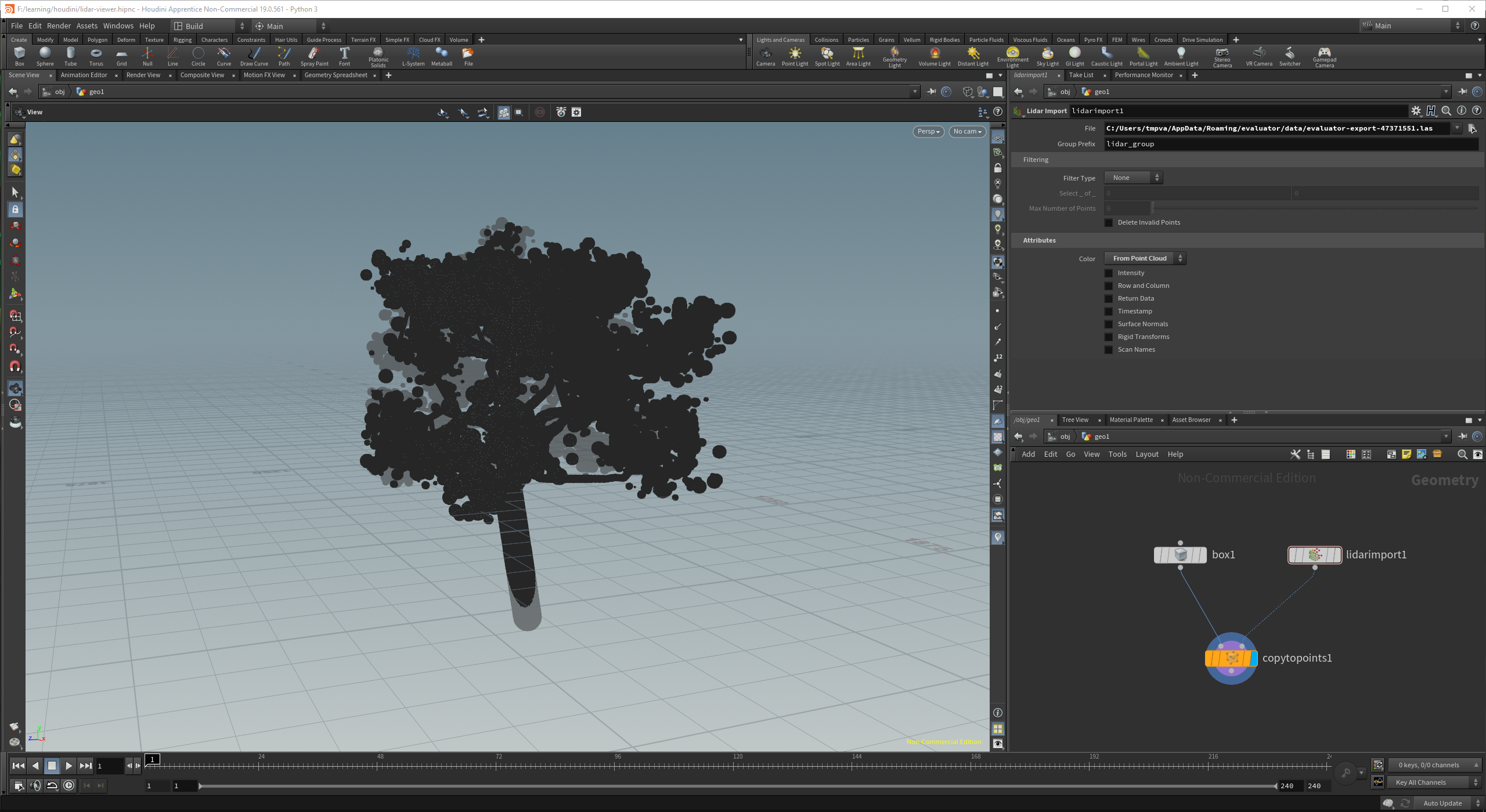
houdini hates this pointcloud
The tree generator generates some really gnarly primitive lists which make for a wonderful benchmarking tool.
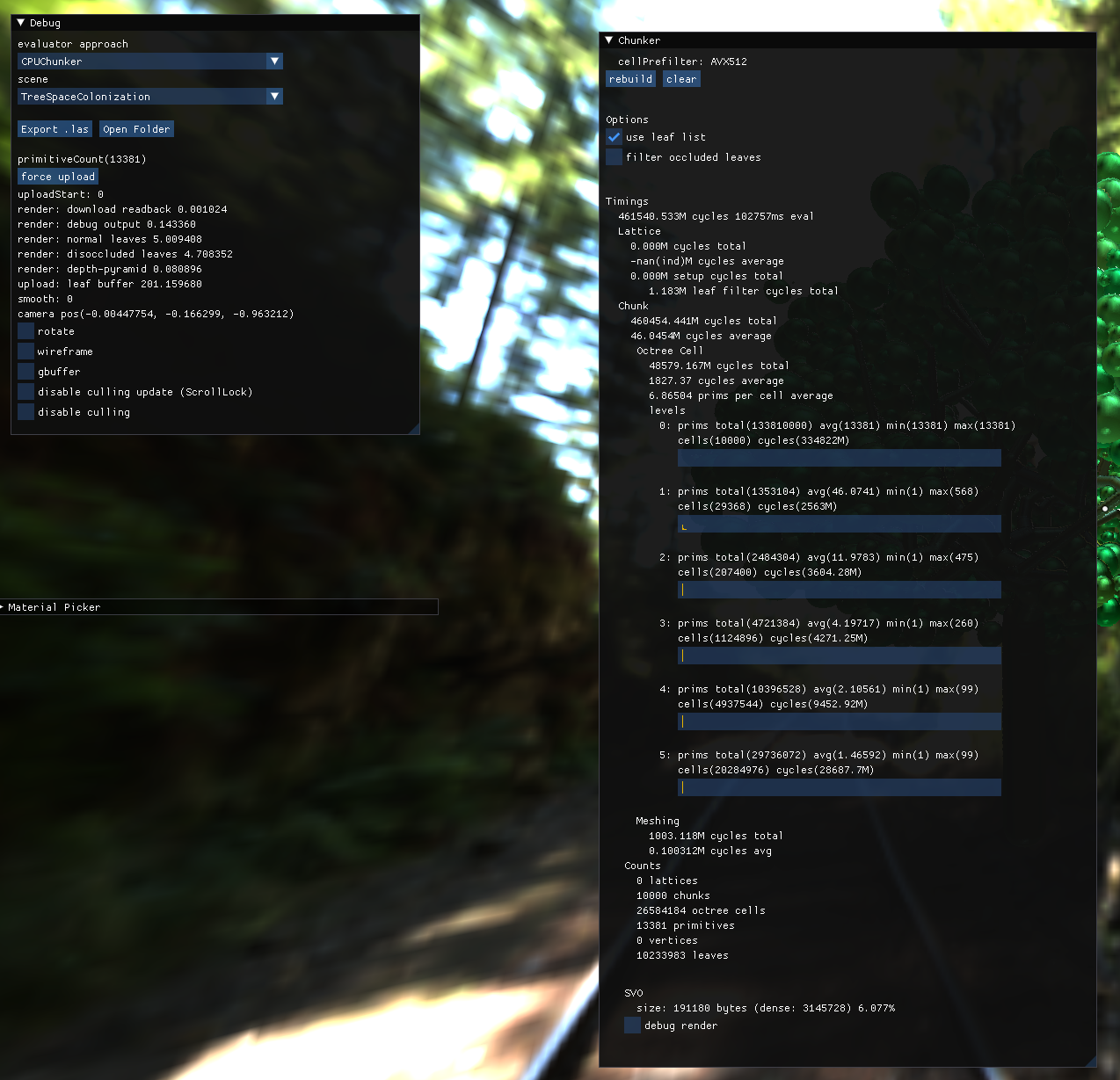
initial tree evaluator timings

bounds filtering at chunk octree level 0 - huge (~4x) improvement!
The next performance problem is when modifying the tree we need to filter out all of the leaves that may have been affected. At this point it was a scan over every leaf which was quite slow!
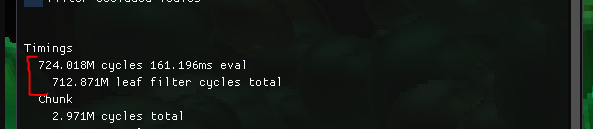
leaf filtering takes ~230x longer than the eval!
The solve for this was filtering at the chunk level instead of globally filtering every leaf.. seems obvious looking back!
chunk based leaf filtering - effectively free
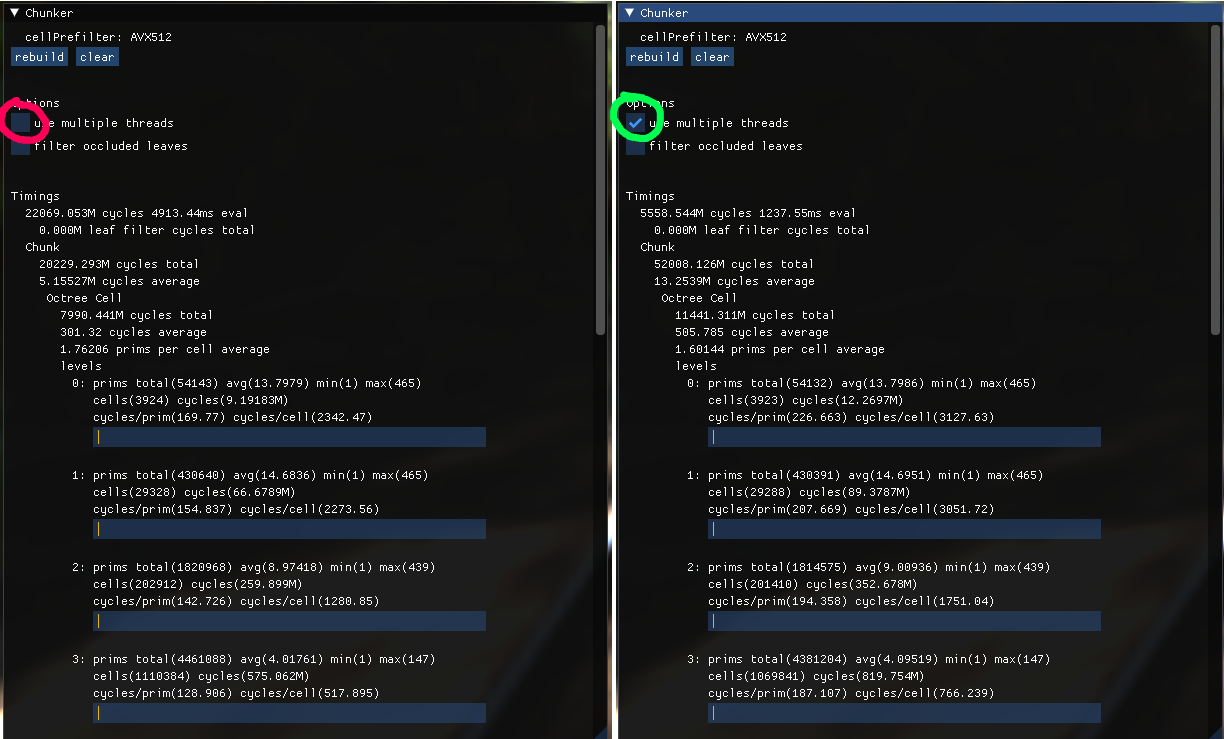
add multi-threaded worker queue - 4x improvement @ 16 threads, not quite ideal.
rendering perf 2-4x improvement by compressing the render list instead of bitmask + degenerate triangles
With that, it was time for some user testing...

chicken head
Things were going pretty well, so I kept pushing. What is better than one monolithic object in the scene? Many instances of many objects. So I started thinking about how the indirections needed to work.
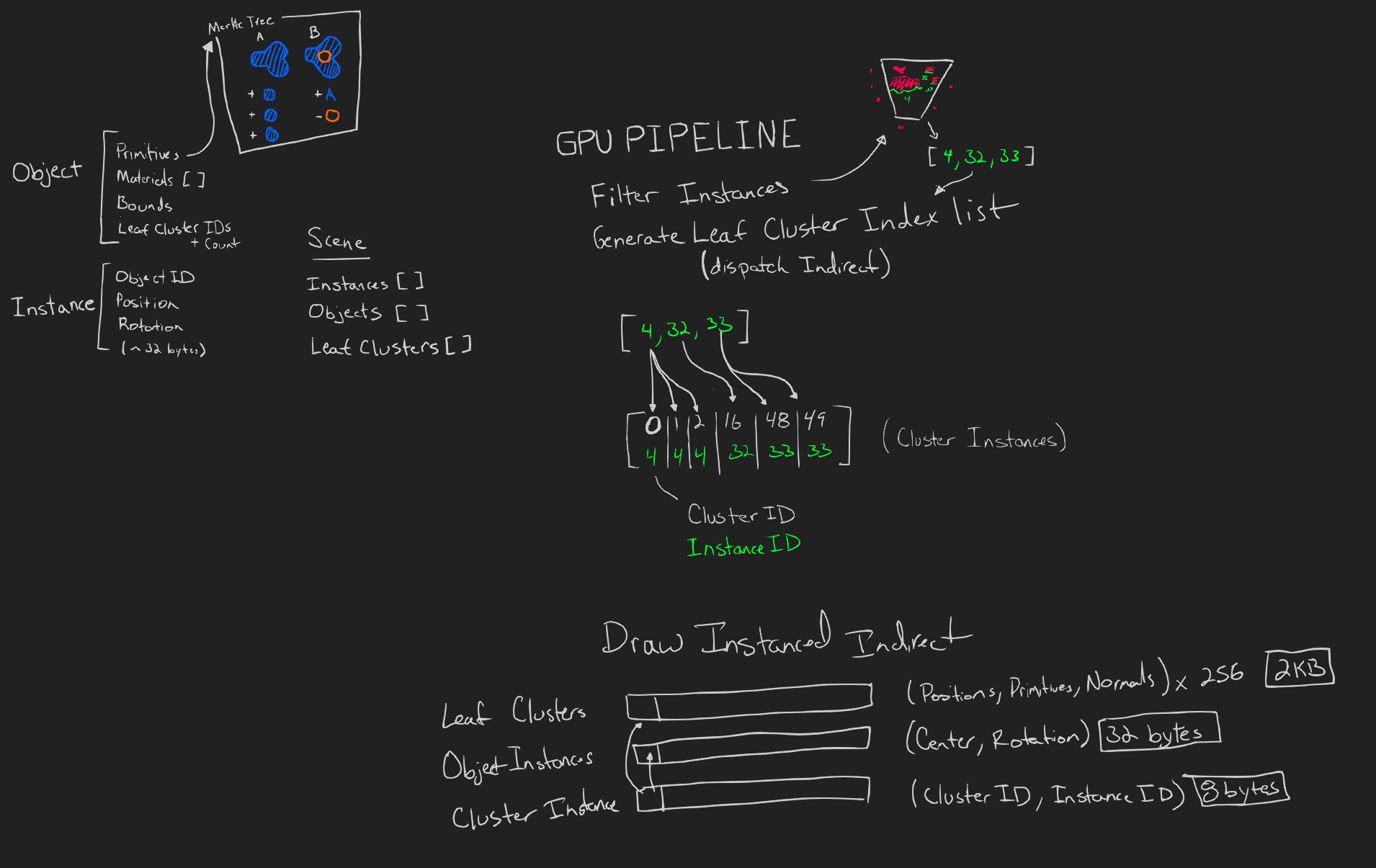
object instancing design
With a loose goal in mind, I took the first step: add instances which are effectively ids that reference the head of a leaf cluster linked list.

first attempt at object instancing (no culling eeeeek!)
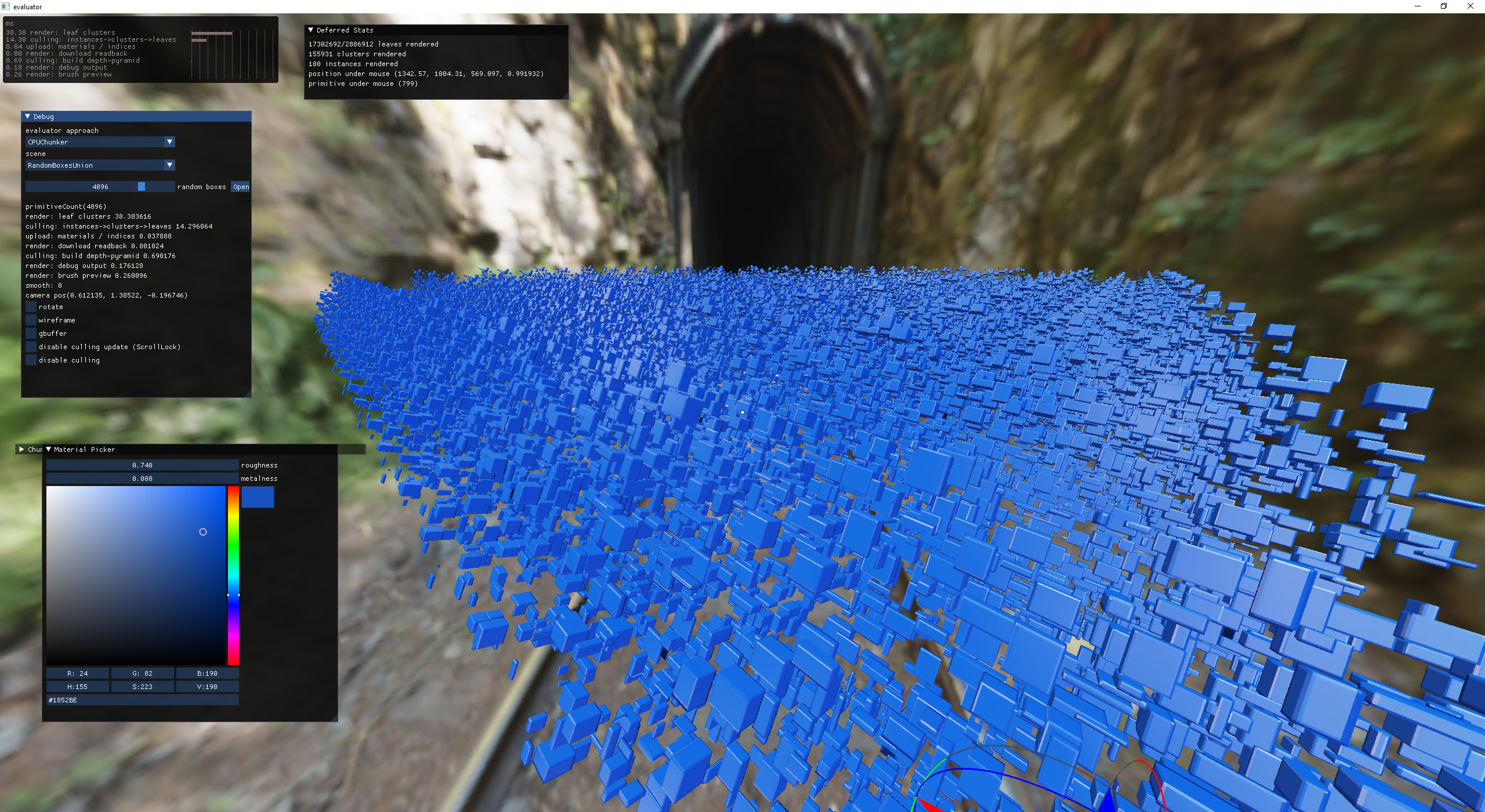
object instancing with leaf cluster hi-z culling
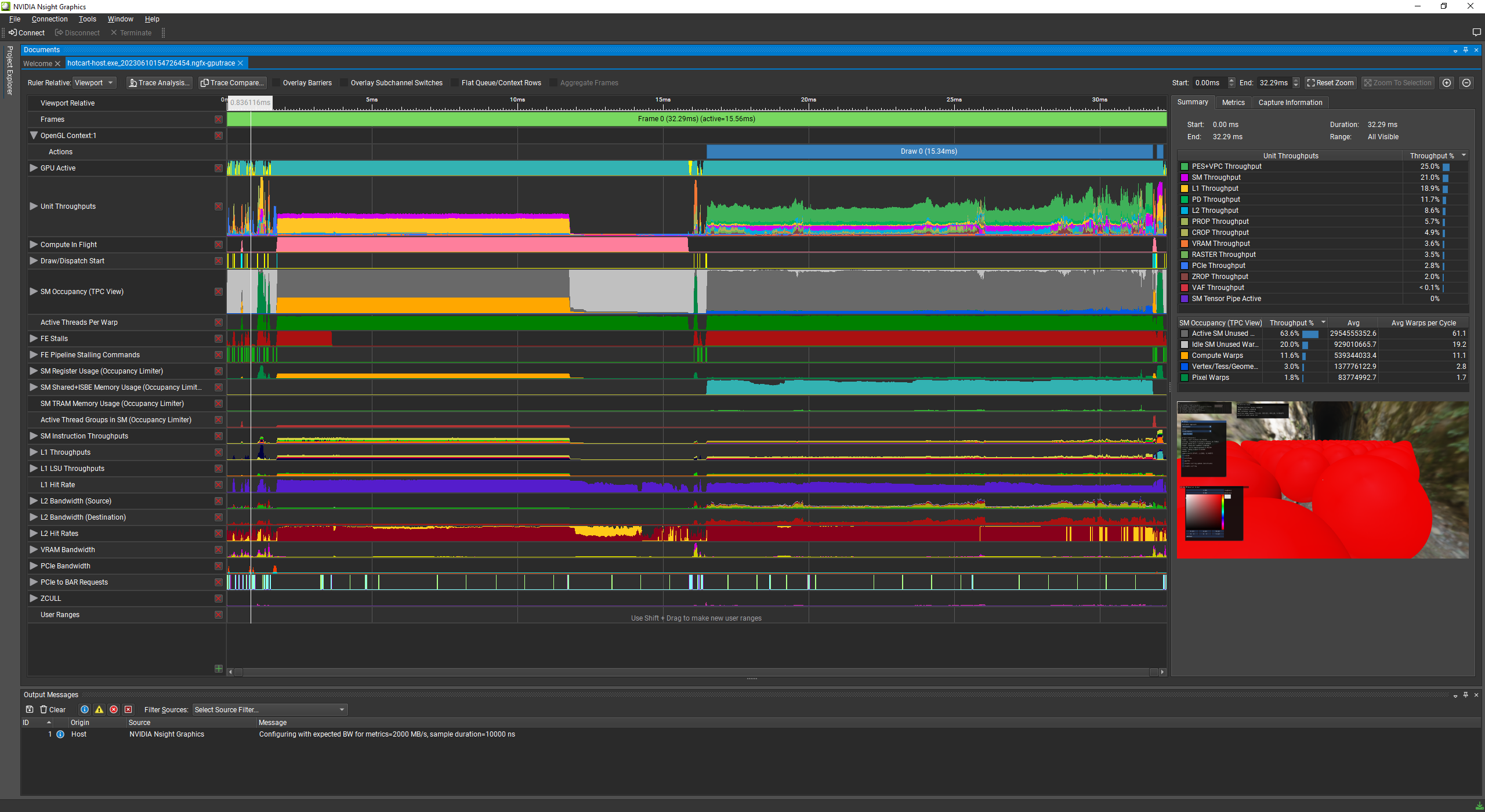
30% SOL on PES+VPC throughput - EW!
Turns out, instancing large fields of points means that MANY triangles are being rendered at sub pixel sizes. To prove this I made boxes that are 1px or less output a constant material - I do better when I can see what is going on.
you don't have to go very far to be 1px (silver shaded in the background)
github/m-shuetz/compute_rasterizer can splat 100M points in ~4ms on my machine - I think this approach will do nicely for rendering distant objects. This project is based on the paper: Software Rasterization of 2 Billion Points in Real Time
The following picture is 10 copies of the tree, overlapped in space which is pretty much the worst case for this technique, as atomicMin is under higher contention.
The .las exporter comes in clutch again as compute_rasterizer is built to load LIDAR files, yay!

splatting in compute is hella fast!
So, obviously I need to write my own compute based point splatter.

splatting in compute (0.37ms)

rasterizing cubes (5.85ms)
Clearly there is a tradeoff between rasterization and splatting here.
splats: better when the size of the leaf is <= 1px
raster: better up close
So let's make a hybrid renderer that plays to each rendering technique's strengths!

raster (1.39ms) compute (0.20ms)
Wait a second, that is like reallly really fast!
how fast??

100 instances: raster (2.31ms) compute (2.19ms) or ~4.5ms total

1000 instances: raster (6.3ms) compute (6.3ms) or ~12.6ms total
Note: this is without instance based Hi-Z culling!
At this point I'm so stoked I threw 1000 trees into a scene.
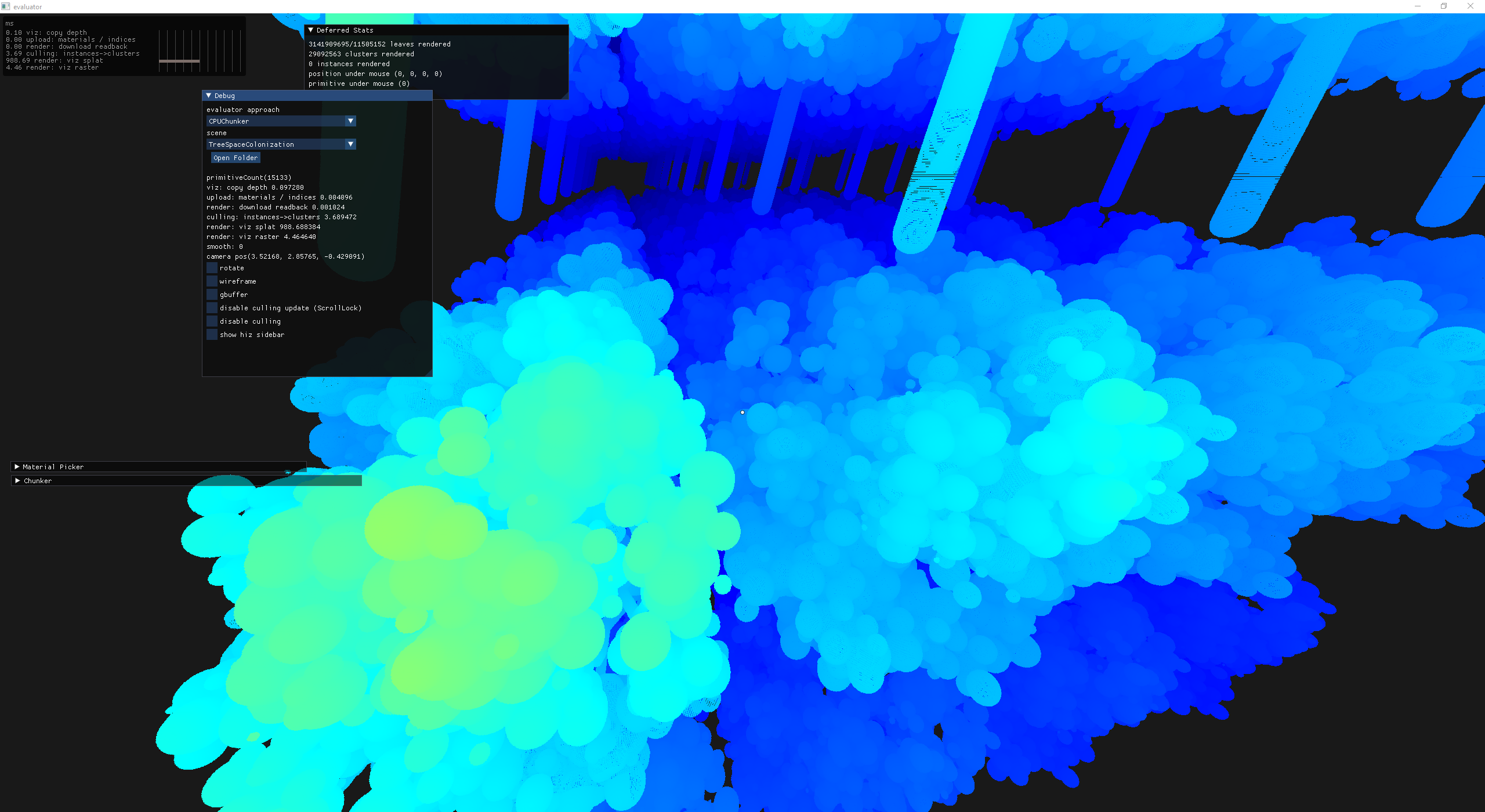
160 instances: raster (4.6ms) compute (988.3ms) or ~992ms total
Ok good, we have a great baseline to improve on. Hi-Z culling at the object level should help quite a bit.
However, there is still more work to be done before jumping into optimizations. At this point I could only instance a single object at a time and I wanted to move to a viz-buffer to reduce the texture bandwidth.

instancing multiple objects into a viz buffer

instancing multiple objects into a viz buffer with normals
After reading through the Nanite paper one of the takeaways for me was that cluster lods were of huge importance to reduce the number of primitives that need to be rendered. So the first step is to get it working, which I did using a simple roulette style sampling
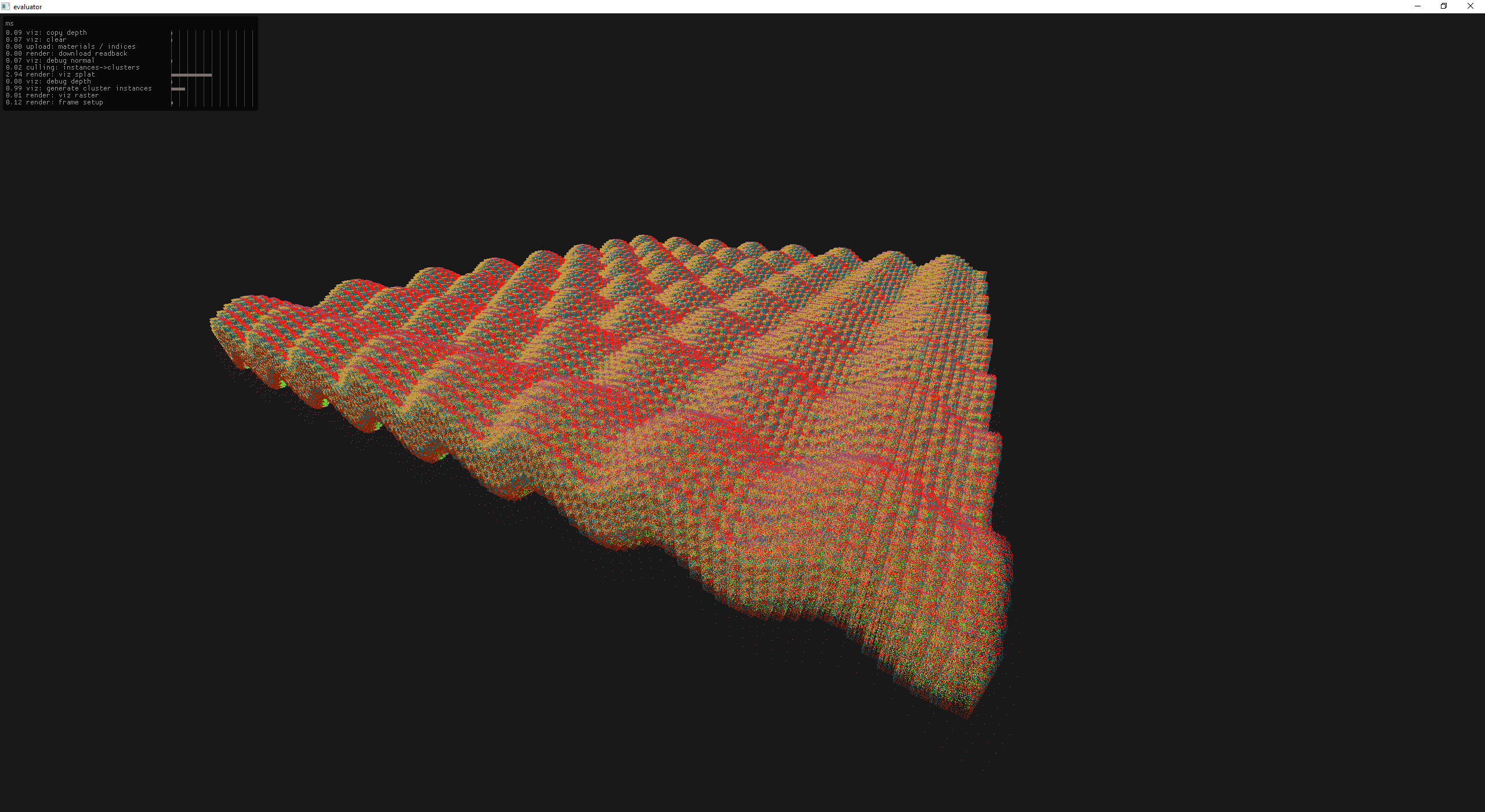
40k wiffle cube instances at fixed lod=3 all splats

moving too close results in a cloud of dust

first round automatic lod picking
and the associated nsight snapshot
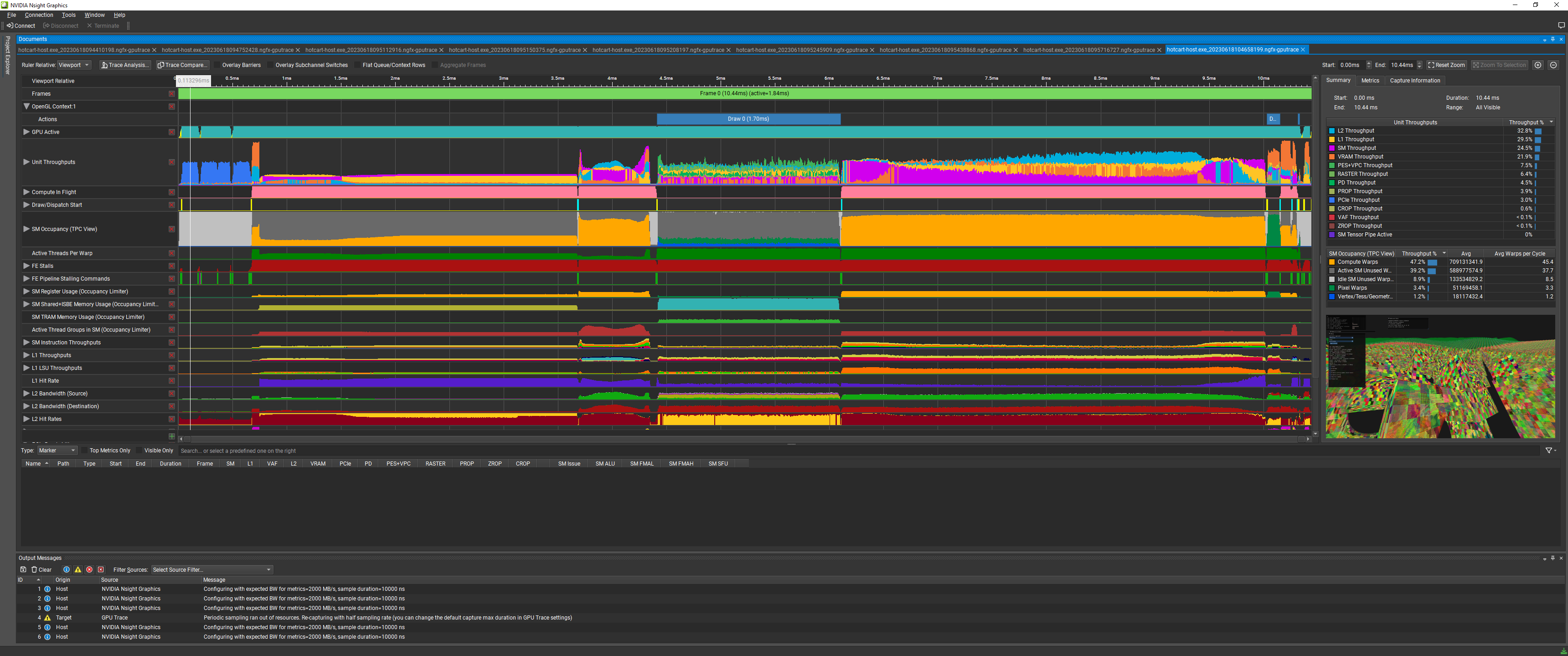
After adding the normals back I got really excited about how many instances I could render!


100k undulating wiffle cube instances @ ~2ms. Clearly there are issues with lod selection!

better hiz culling (single sample from HZB) and better splat size

a view from a different perspective with the hzb viewport locked
Unfortunately there are still a ton of holes in the splat renderer. I spent quite a while trying to patch these holes.

when splats are too small it creates holes

perfect splat sizes at the cost of 130ms per frame!
Why is the optimal splat size so innefficient?
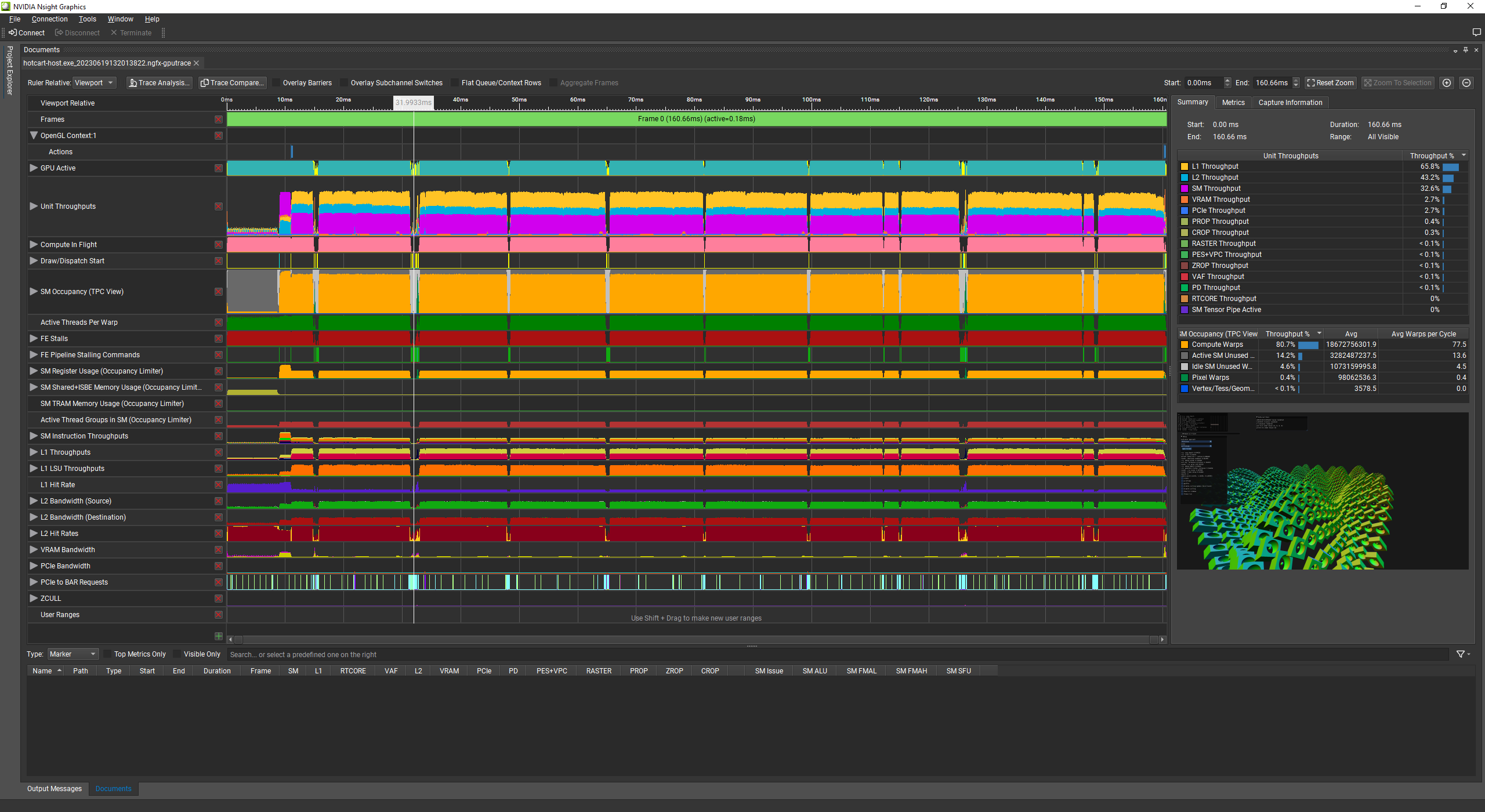
nsight capture says: you're memory bound.
Here's nsight capture if you are curious: fixing-splat-holes-perfect-at-130ms.zip.
So instead of getting sucked down an optimization rabbit hole, I decided to try and fix the original problem with holes and quickly realized that the leaf clusters were also a source of holes.

cluster shaped holes
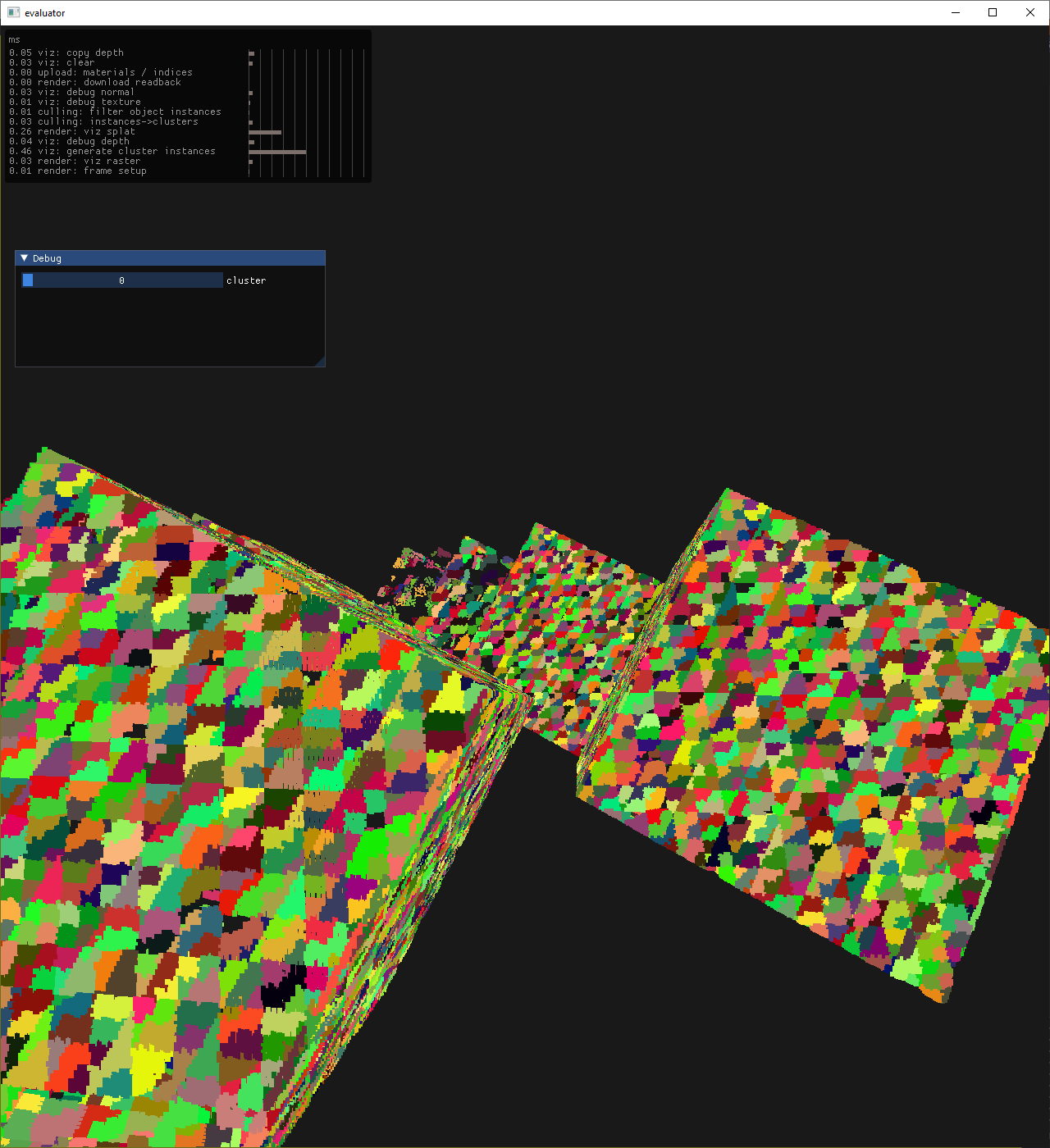
cluster shaped holes (cluster coloring)
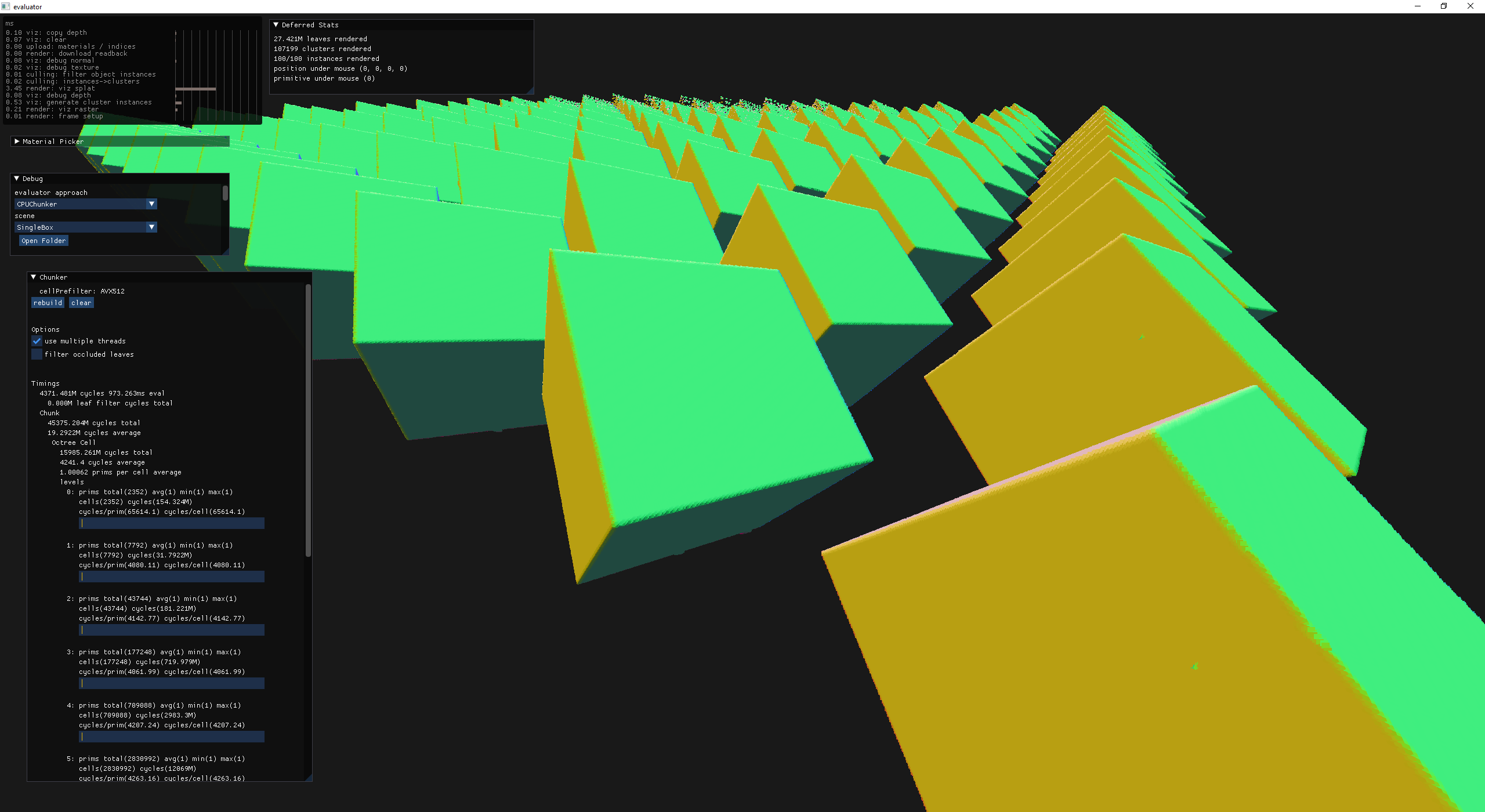
avoid enqueing empty octree nodes while building clusters!
After this there were a few more cluster generation related bugs, some tuning of splat size and raster cut-off, and of course some more Hi-Z tweaks.

1000 trees to debug Hi-Z occlusion culling
At this point things are working pretty well, but instead of adding materials back I decided to go on a tangent of actually using this system to do some procedural generation.
Starting with a leaf with the form designed using this Ovate Leaf Form desmos calculator

a single ovate leaf built by spamming cylinders
Since I've been working so hard on implementing instancing, I made a little bush of these leaves.

a bunch of ovate leaf instances
You may have noticed that there were some artifacts in the above image and I bet you couldn't of guessed that they were cluster lod related. So that got fixed next.

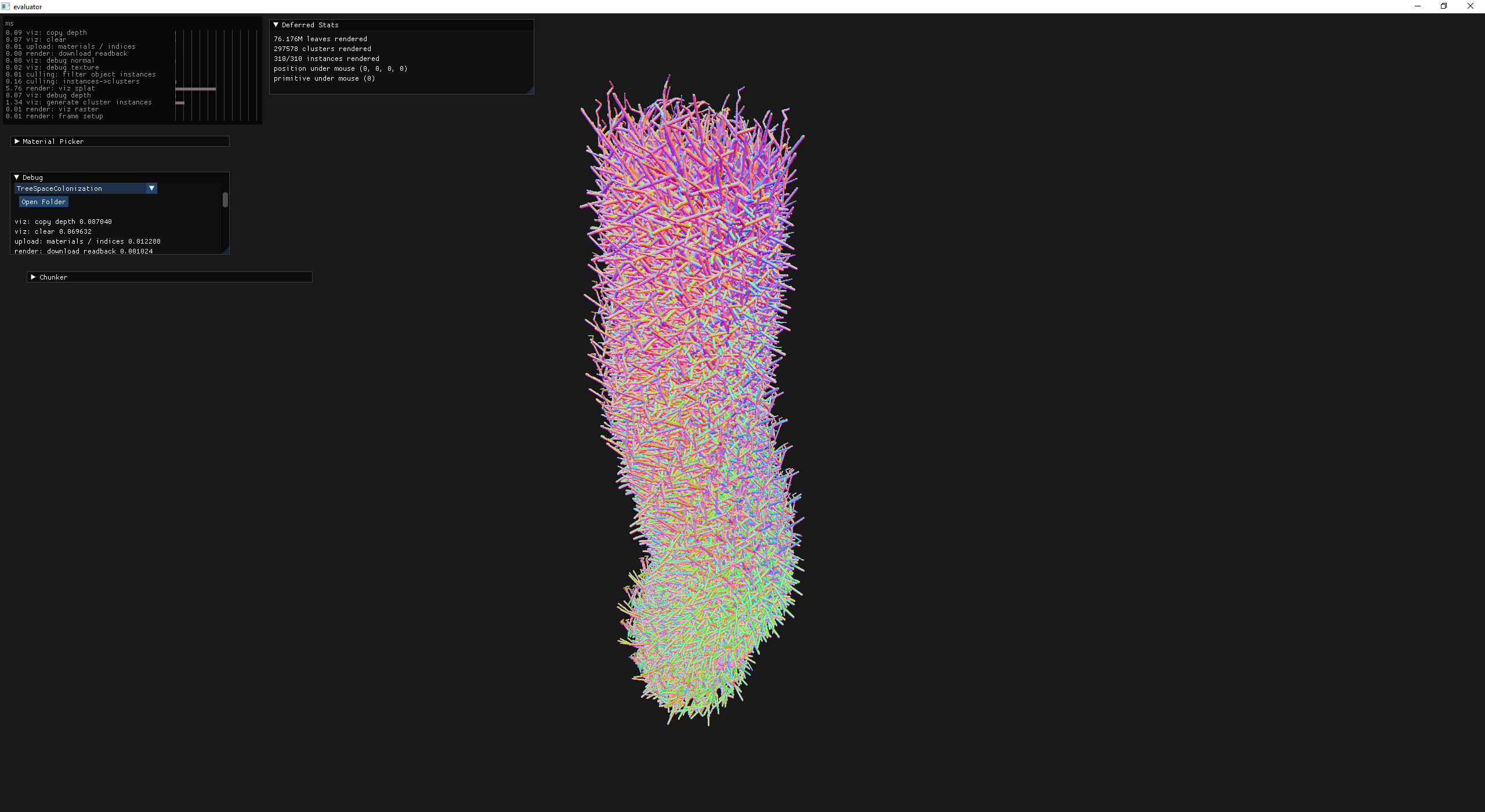

At this point, things appear to be working pretty well. On larger scenes the thing that computes what clusters at what lod (e.g., the viz: generate cluster instances profiler line) dominates the time spent and prompted me to to atleast consider a different approach.
Back to procgen, I decided to spend a bit of time exploring continuous noises.
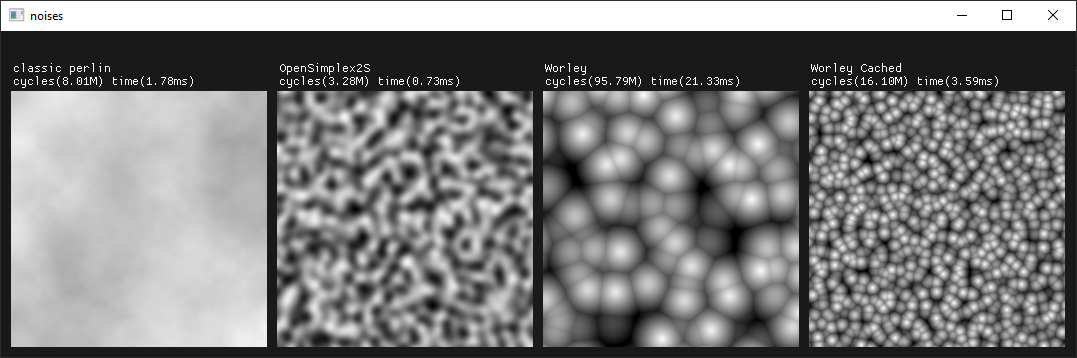
collecting / implementing noises
Bah, I found some issues with my Hi-Z implementation, so I added a seeing tool in the form of a top-down view. The idea is pretty simple, for every potentially rendered cluster draw a rect at a certain location on the screen which acts like an orthographic perspective. The trick is getting the scale / bounds correct but it is a very low effort way of inline debugging. This happens in the filter-cluster-instances compute shader which has been passed a debug texture that gets rendered over the scene as a final pass.
left: cluster culling info
yellow = frustum culled
red = depth culled
green = passing
middle: jet colored linear depth
right: random colored hiz mip level
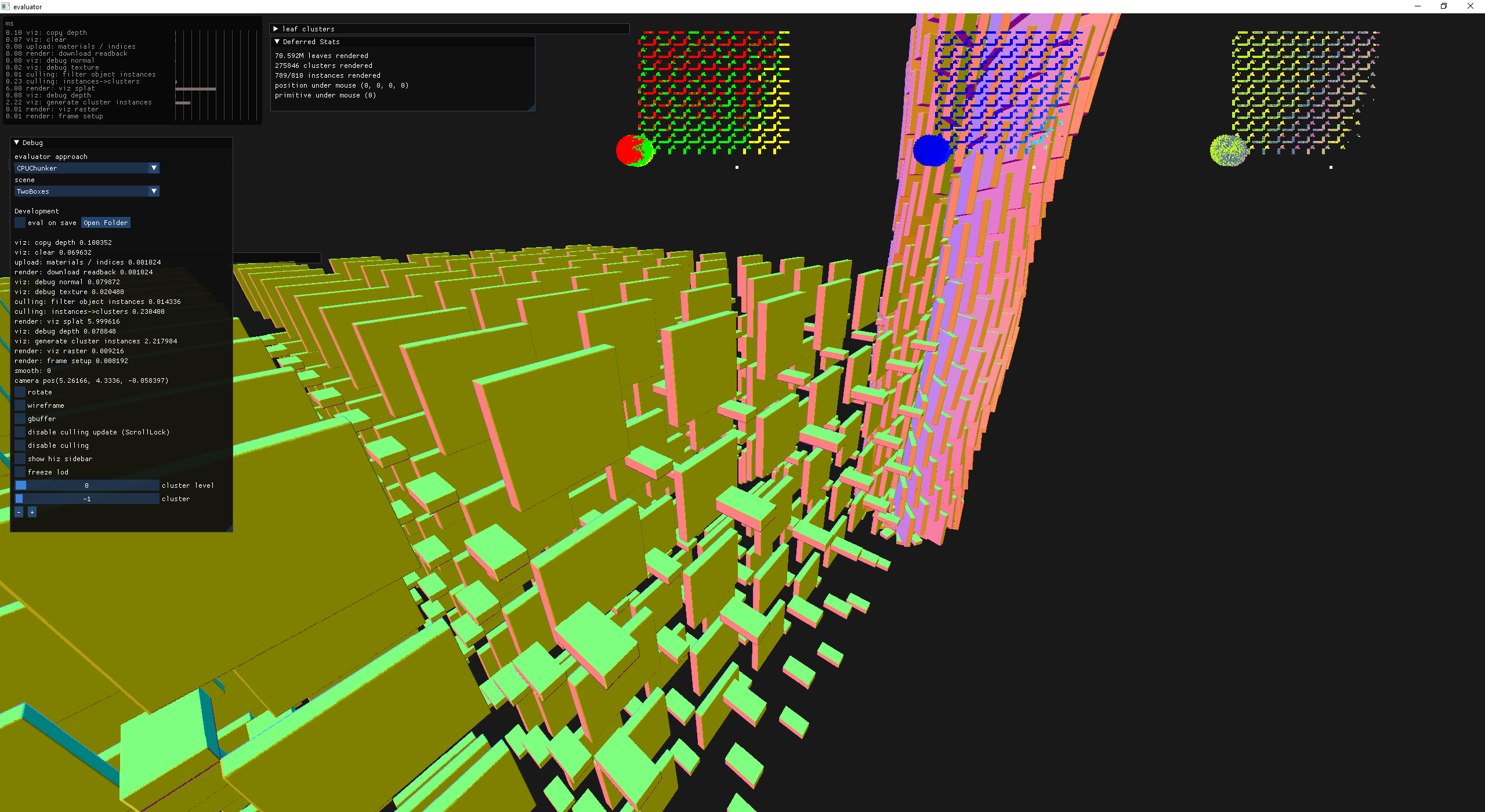
Hi-Z debug view
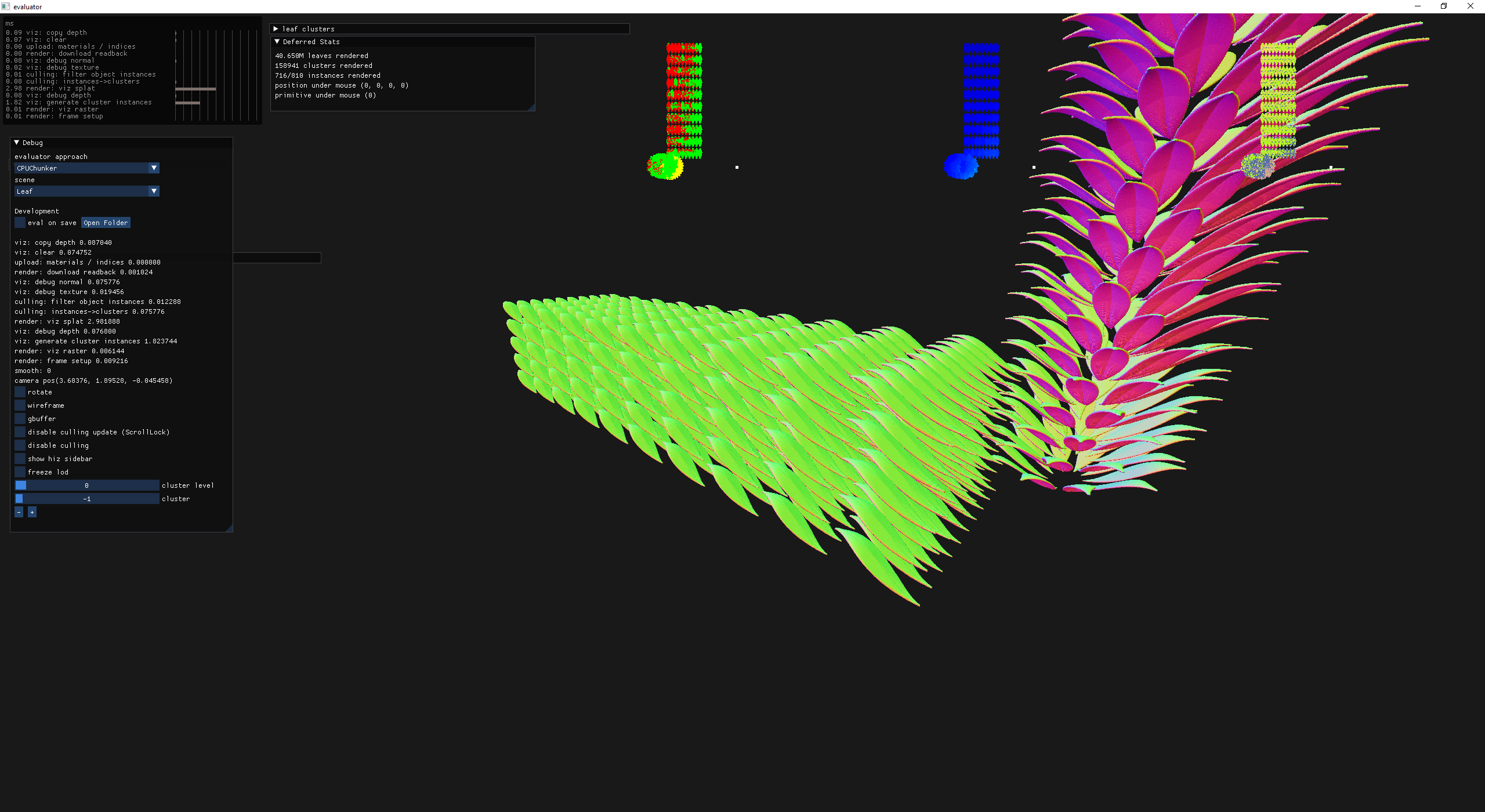
another example of Hi-Z debug view
This debug texture came in clutch so many times, I also used it as X-Ray vision to see things that were being culled by Hi-Z. It also gave me an easy way to overlay the Hi-z texture and all of it's mips.

drawing rectangles around culled instances
July
Insipired by the Modular Ruins C Unreal Engine asset pack, I decided to start procedurally generating some stone/brick tilesets.

building some re-usable tiles
Now with all of these tile sets I can start building some primitive things, by manually instancing objects and positioning them in the scene.
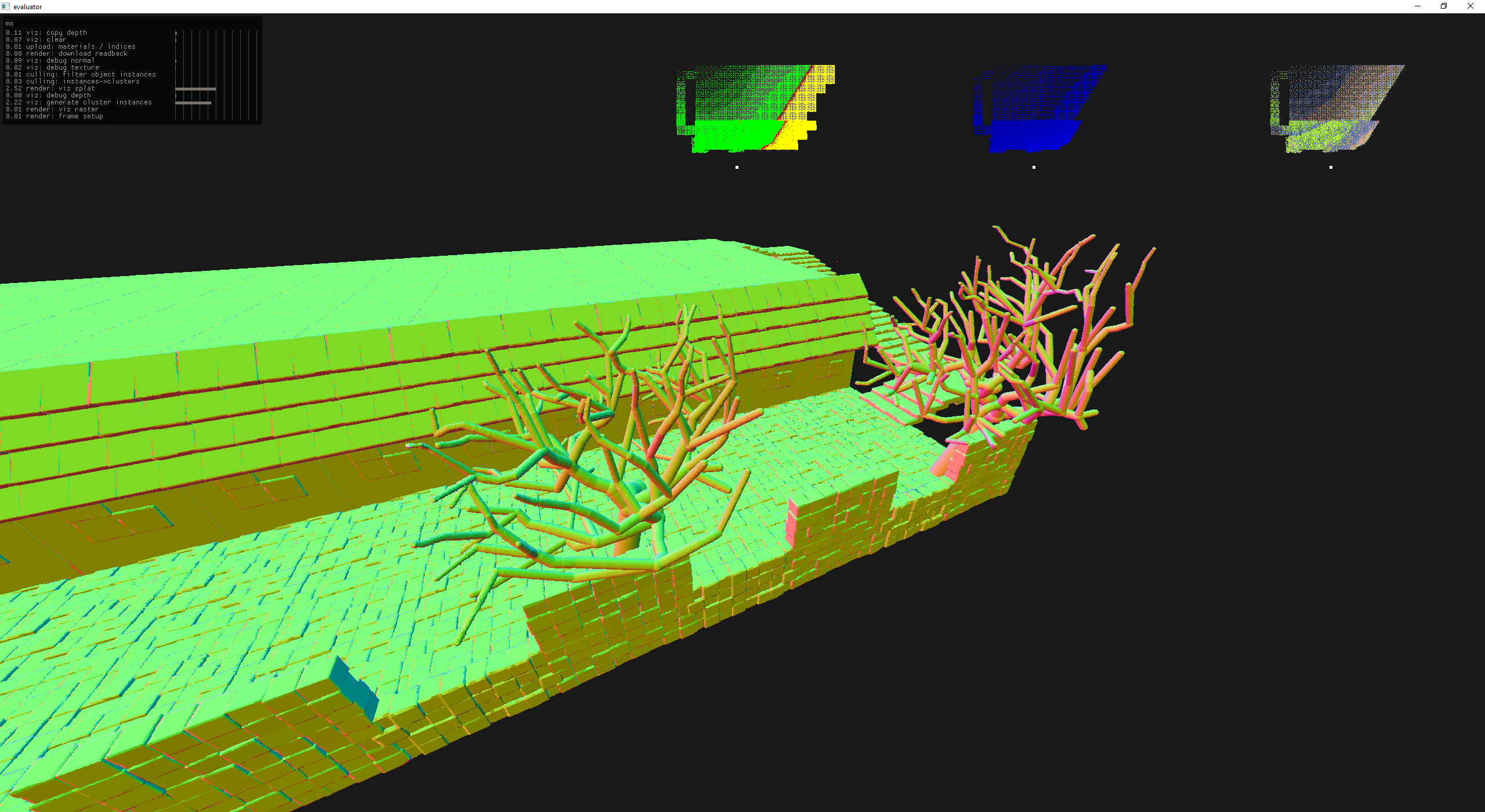
an attempt at ramparts
The staircase in the back right of the scene was quite a pain to layout in code so I started to consider the possibility of procedurally placing tiles. Since I was just working on a staircase, why not make a spiral?
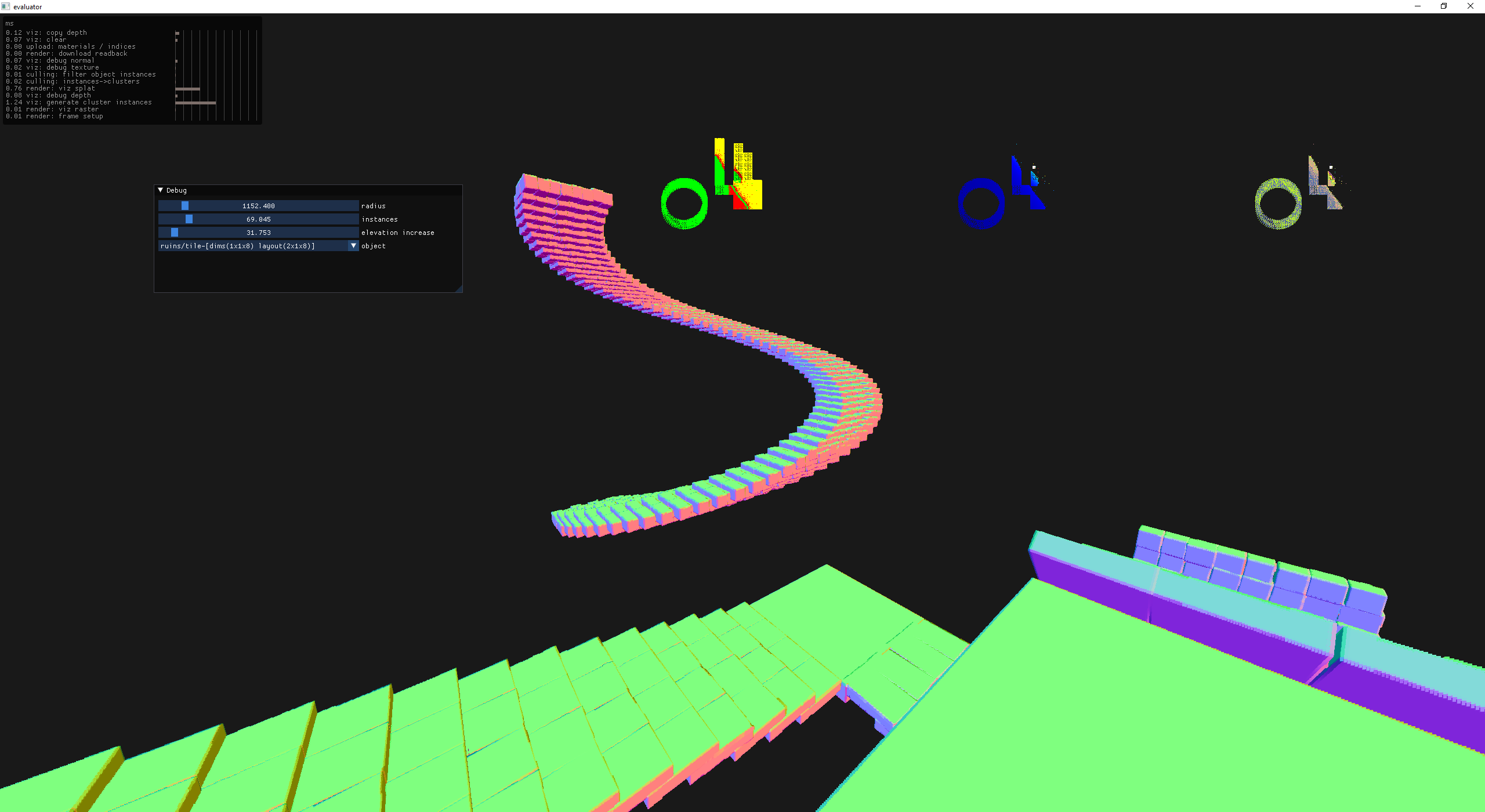
a simple spiral - no local orientation changes
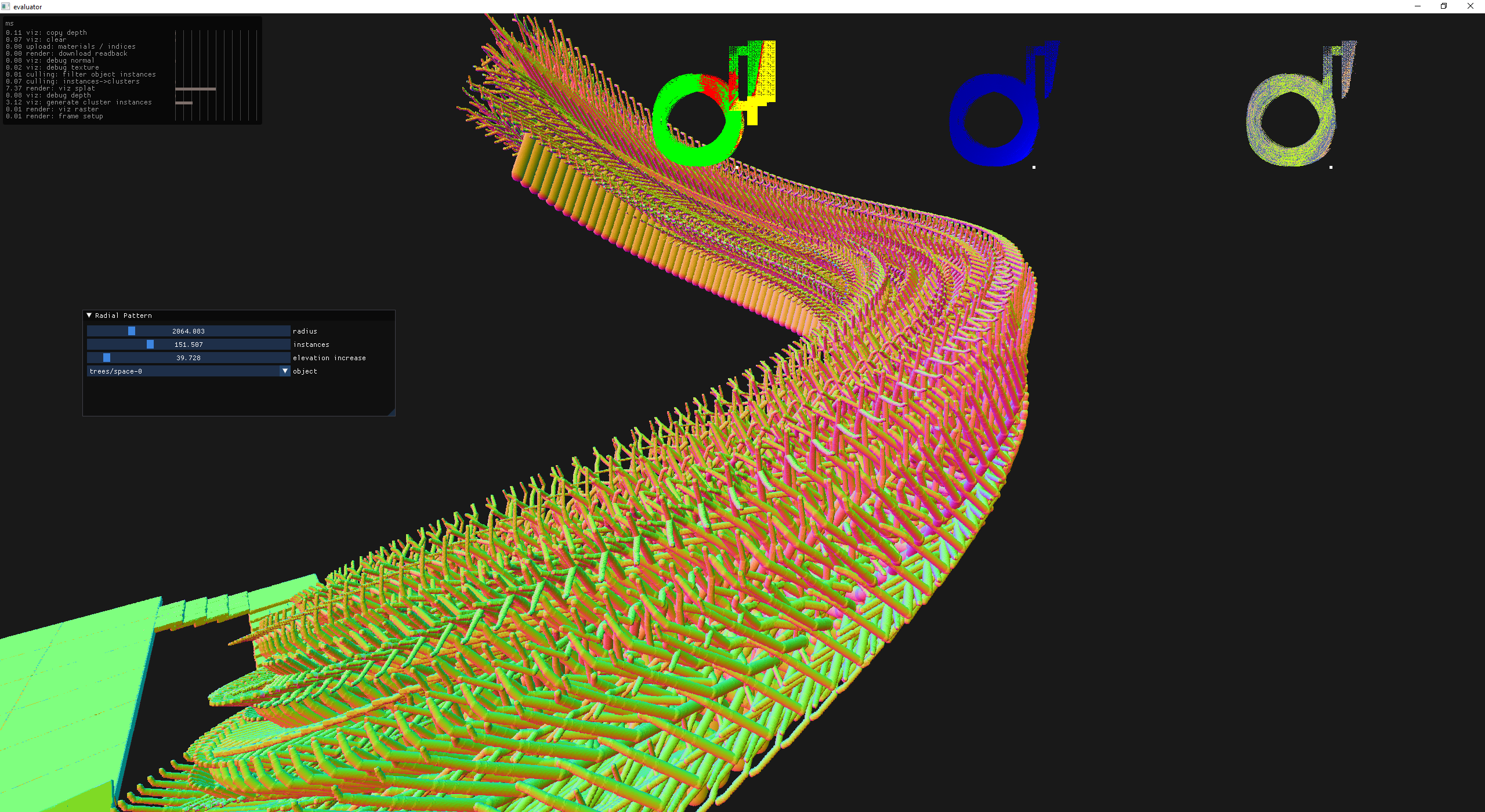
a spiral of trees
add in local transforms
Why not linear instancing?

linear instancing with a twist
Procedural generation at the instance level is actually a ton of fun! I got to thinking about the tree and how it had no leaves. The original spheres as leaves was not great and I'd like to instance clusters of leaves and attach them to the ends of the branches. Hrm, how do I do that if the object is already done generating? A list of locations need to be stored along with the object that can denote where things can be attached... I think other engines call this a socket system, so I'll go with that!

tree sockets

tree sockets with a different seed
Proud of myself, I set my next goal to bring the materials and image based lighting back.

IBL with global roughness/metalness and cluster coloring

add materials to the tree and attach wiffle boxes

add materials to the tree and attach spheres
Things are starting to look better, but the tile materials are so boring!

procgen more tiles

I love these randomly jittered orientations!
I have a goal of being able to perform CSG on object instances, but noticed that a cut would propagate its material instead of what I'd expect in some cases which is: show the inside of the object.

allow cuts without applying material

add a 2 meter tall person at 500 splats per meter

add stb to the noises app
I had recently watched Wave Function Collapse in Bad North and was inspired to give WFC a try.

visualize uncertainty

doing something.. just not the right thing

closer
After making this interactive, it was hard not to play with!








So that was a nice distraction, but the result doesn't really have immdeiate applicability into the main project, so I moved on to material blending.
replace primitive ids with material hash

before

graph colored material hashes

degenerate case - fully smooth + metalic red blended with rough green
Objects Made of Objects

modifying an existing object
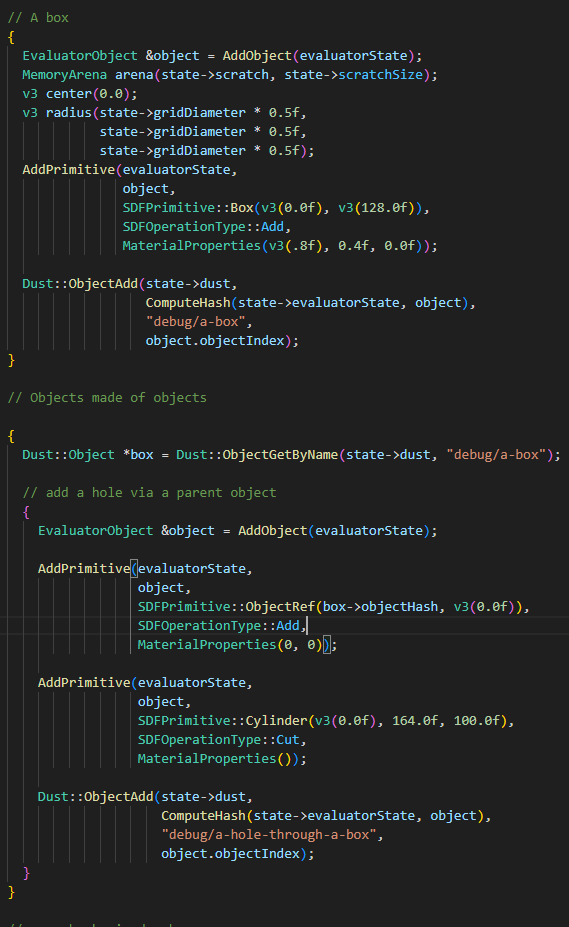
modifying an existing object
Instances of Instances

instances of instances (graph)
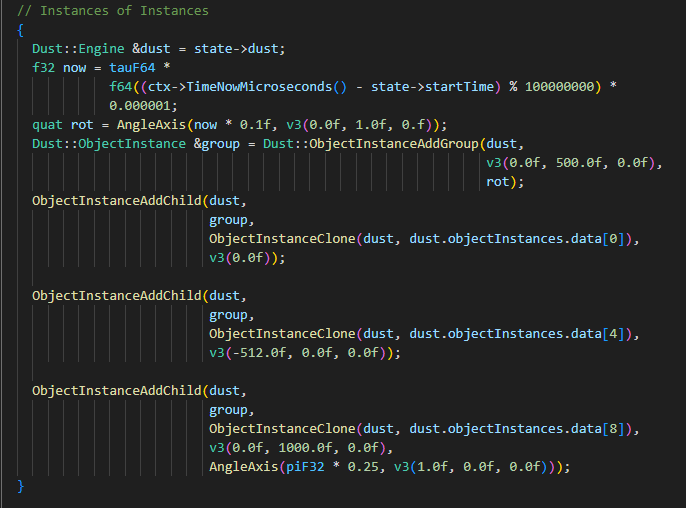
Turns out instances of instances implemented via *AddChild has some really annoying properties, the biggest one is that you can form graphs. So I took a page out of Valve's hand book and limited entities to having a single parent.

instances of instances (tree)

SDF Operations: shell and elongation
Debug Rendering
I had been adding a bunch of common code to Dust when I realized that I barely had any sort of debugging primitives (e.g, sphere, cone, box, etc..)
debugging lines / circles / points

debugging spheres / cylinders / boxes
debugging box w/ dimmed backfaces

debugging sphere / cylinder / capsule dimmed backfaces
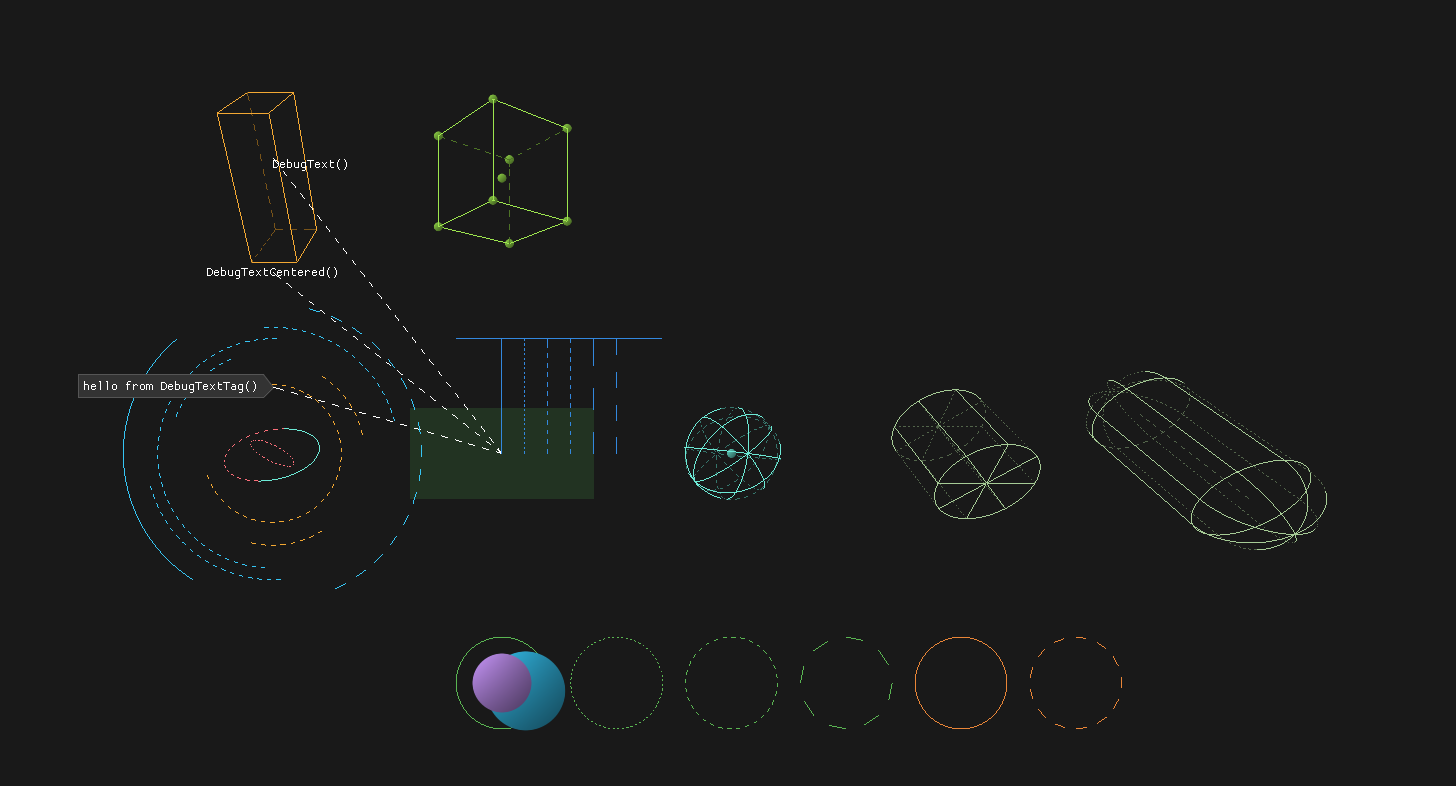
debug text labels

eliminating bogus event models for Dust
To prove this system out, I built a little top down shooter game over ~2 weeks using the debug geometry for and an entity system inspired by the source engine (via the wiki)
This is a WIP, if you found this and want more, let @tmpvar know!
August
I started thinking about all of this stuff I've been doing from the past couple years and realized that from an external perspective it looks like I just vanished. I've grown very tired of social media websites and the psychological issues that it causes.
first post on the new tmpvar.com!
I also spent some time designing and cutting out some mechanical bits for a proof of concept human input device that works like a pen but has force feedback.
designing an encoder wheel
designing a modular arm segment

tumbled parts
September

added an overhead light to the cnc desk!
Simon Brown posted a tip about using the signed bit to differentiate between -0 and +0 which makes isosurface extraction more robust.
As soon as I saw it I knew it was the source of some issues that I had been seeing but hadn't been able to identify.
const IsNegative = (function () {
let isNegativeScratch = new DataView(new ArrayBuffer(8))
return function IsNegative(value) {
isNegativeScratch.setFloat64(0, value, true)
let uints = isNegativeScratch.getUint32(4, true)
return (uints & 1 << 31) != 0
}
})();
static inline bool
IsNegative(f32 a) {
u32 *p = (u32 *)&a;
return (*p >> 31) != 0;
}
fn IsNegative(v: f32) -> bool {
let bits = bitcast<u32>(v);
return (bits & (1<<31)) != 0;
}
Applying this to the chunker almost cut the number of collected leaves in half (1.7M -> 900K) making evaluation ~2x faster. What a huge win from such a simple concept! Thanks SJB!
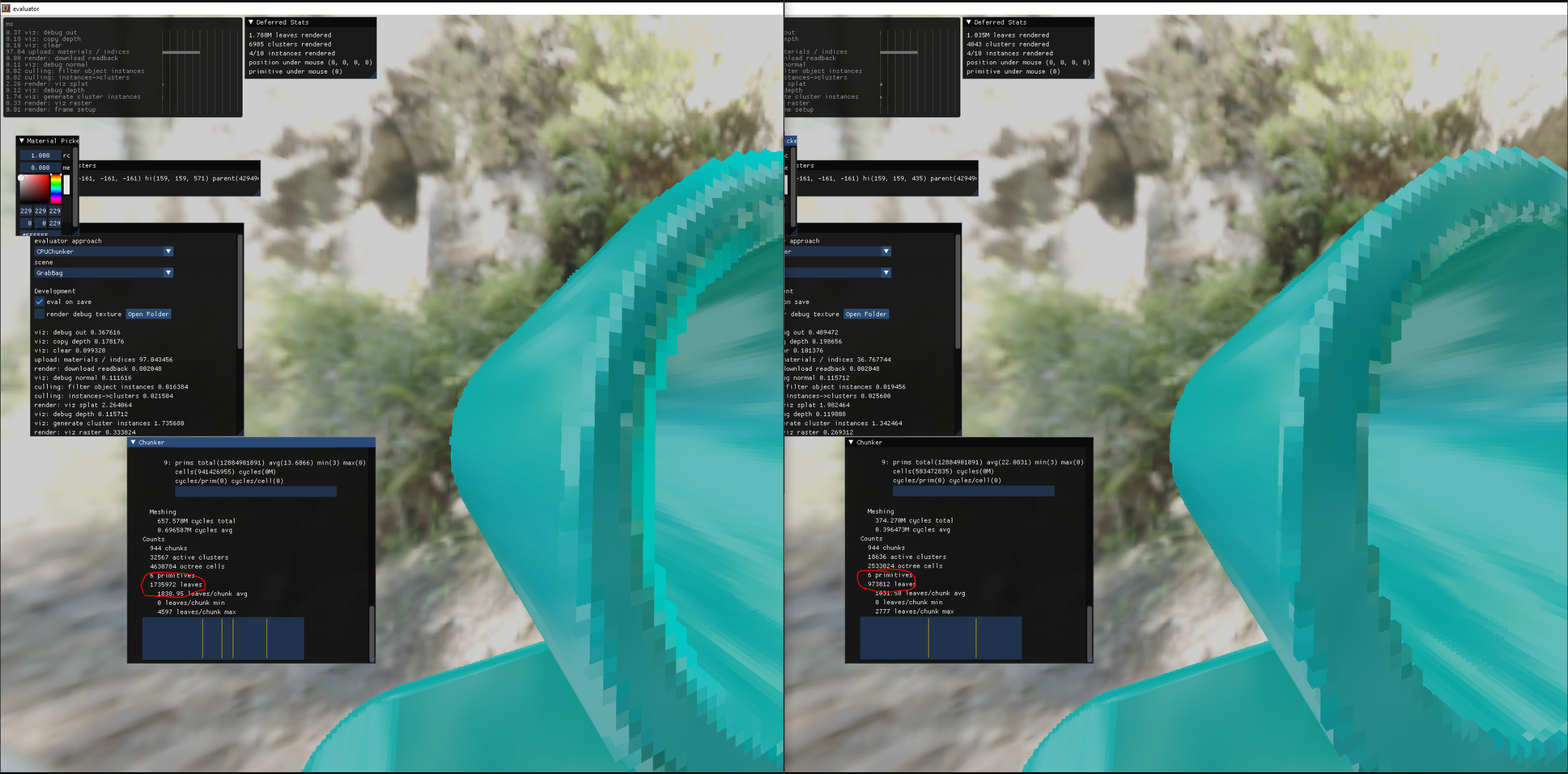
negative bit trick for much win
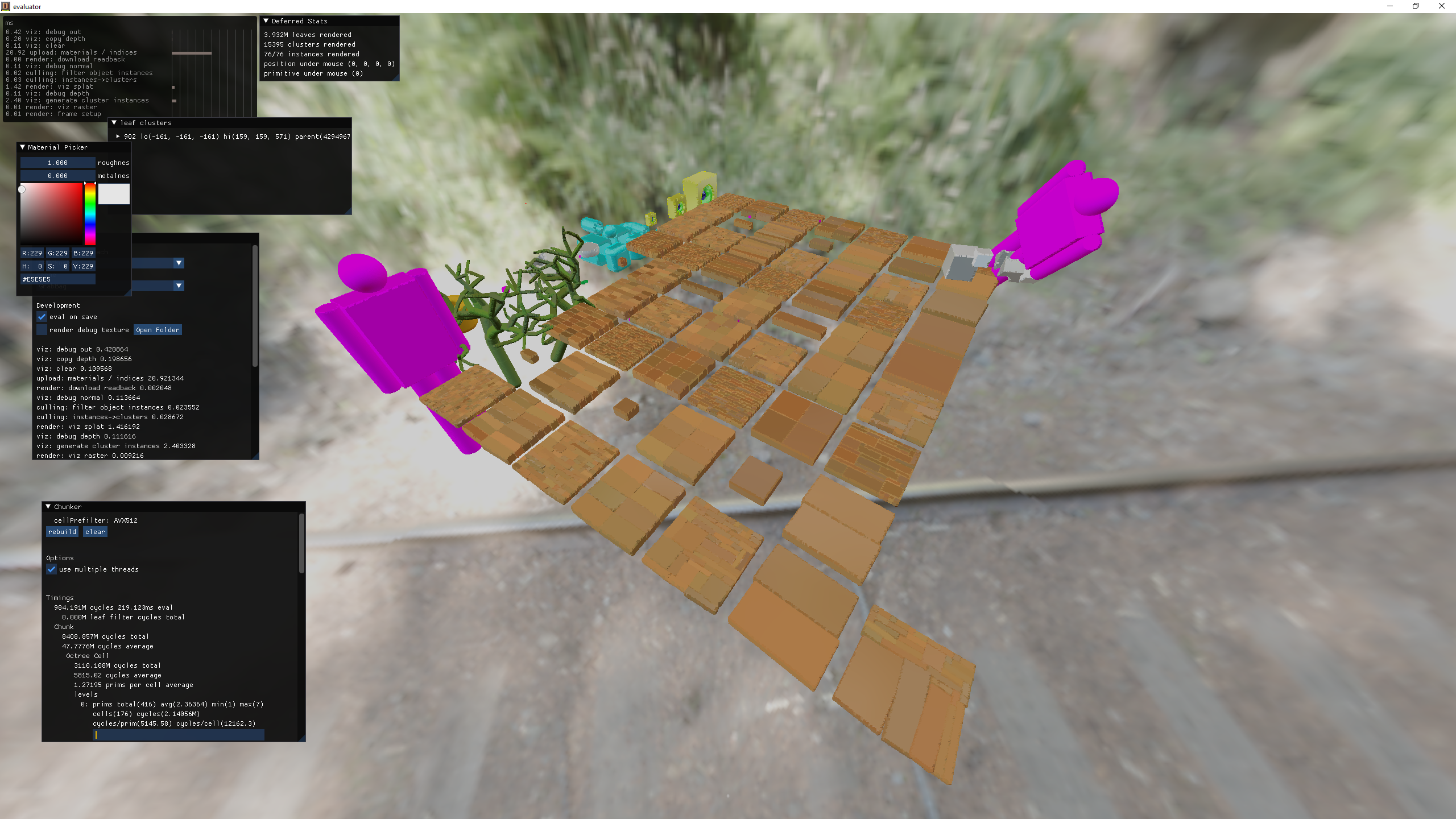
negative bit trick grab bag testing

weird landscape made of spheres and perlin noise

weird landscape made of spheres and perlin noise
Radiance Cascades
On August 8th, Graphics Programming weekly - Issue 299 - August 6th, 2023 popped into my inbox and and the first item is a talk by Alexander Sannikov at Exilecon. Mixed in with a bunch of other techniques that I really want to try was this notion of radiance cascades - a constant time GI implementation. Given that I've been stuck using Image Based Lighting for the splat renderer, this was really interesting. I'd really like to add dynamic lighting.